

Imagine you’re reading through a transcript from yesterday’s team meeting. The text is accurate, every word captured correctly. But there’s one problem: you have no idea who said what.
So tell me about how you got started in podcasting. Well it really began when I was working in radio actually and I realised that the format was changing and people wanted something more conversational more on-demand. Right and did you have a background in audio production at that point. Not really I was self-taught I bought a cheap mic and just started recording in my spare bedroom honestly.
Every word is there. The transcript is still useless.
This is the problem speaker diarization solves. Without knowing who spoke when, multi-speaker audio remains a wall of text. With speaker diarization, that same transcript becomes a structured conversation you can actually use.
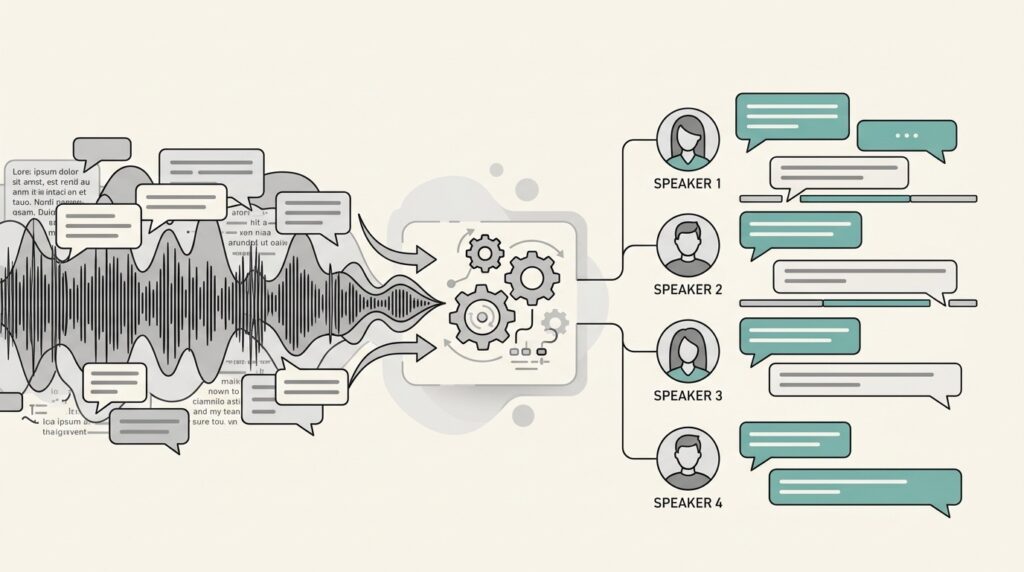
The Problem With Unlabeled Transcripts
Here is what happens when you transcribe multi-speaker audio without diarization. You get a flat stream of text with no attribution. No speaker labels. No way to tell who made which point, who asked which question, who committed to which action item.
For a 60-minute meeting with four active participants, that’s 60 minutes of dialogue you cannot parse. Want to find what the CEO said about Q3 targets? You’ll need to listen to the recording again. Need to confirm who volunteered to own the project? Back to the audio.
The transcript was supposed to save you time. Instead, it created more work.Here’s the short version: transcription converts speech to text. Diarization identifies who produced each piece of speech. They’re separate processes that work together, and without the second one, the first one often misses the point.
What Is Speaker Diarization?
Speaker diarization is the computational process of partitioning an audio recording into segments based on who is speaking. The name comes from “diary” (the idea of creating a record of who said what and when). In practical terms, it answers a simple but technically difficult question:
Who spoke when?
When diarization works correctly, your transcript looks like this:
Speaker 1: So tell me about how you got started in podcasting.
Speaker 2: Well, it really began when I was working in radio, actually. I realised that the format was changing and people wanted something more conversational, more on-demand.
Speaker 1: And did you have a background in audio production at that point?
Speaker 2: Not really. I was self-taught. I bought a cheap mic and just started recording in my spare bedroom, honestly.
Each speaker is identified and labeled consistently throughout the document. The transcript is immediately readable as a dialogue. Speaker labels can then be updated from “Speaker 1” and “Speaker 2” to actual names (a one-minute job rather than manual tagging across the entire document).
It’s important to understand what diarization is not. Speaker diarization assigns anonymous labels (Speaker 1, Speaker 2) based on voice characteristics. It does not identify who the speakers actually are. That task, called speaker identification, requires pre-enrolled voice samples and is a separate (supervised) process. Diarization is unsupervised: it works on unknown speakers without any prior enrollment.
How Speaker Diarization Works
Modern speaker diarization systems follow a four-stage pipeline. Let’s break it down.
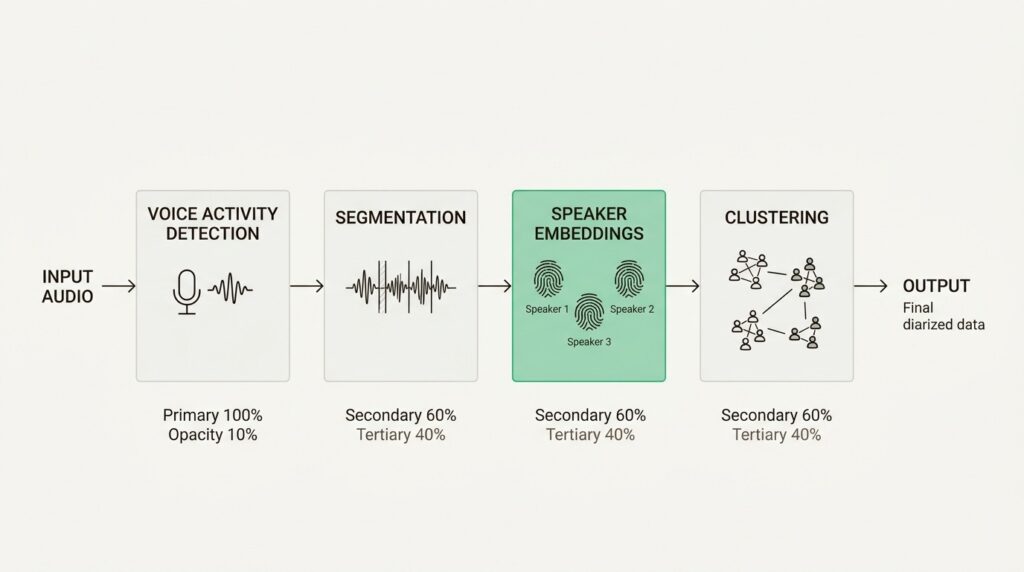
Stage 1: Voice Activity Detection (VAD)
The system first identifies which segments of the audio contain speech versus silence, background noise, or music. This step filters out non-speech portions so the diarization process only analyzes actual voice content. WebRTC VAD is a commonly used open-source solution for this task.
Stage 2: Segmentation
The speech portions are divided into small chunks, typically 0.5 to 10 seconds each. Smaller windows help ensure segments contain only one speaker, though they produce less informative representations. Modern systems use neural models to produce segments based on detected speaker changes rather than fixed windows.
Stage 3: Speaker Embeddings
Here’s where real intelligence happens. The system creates “speaker embeddings” (digital fingerprints that capture unique voice characteristics). These embeddings encode patterns like vocal pitch, speaking rhythm, accent markers, and tonal qualities that make each voice distinct.
Traditional statistical representations like i-vectors have been largely replaced by embeddings like d-vectors and x-vectors produced by neural networks trained specifically to distinguish between speakers.
Stage 4: Clustering
Finally, the system groups segments with similar voice fingerprints together and assigns consistent labels throughout the recording. Common clustering approaches include:
- Spectral Clustering: Uses eigendecomposition to group similar embeddings
- Agglomerative Hierarchical Clustering: Builds a hierarchy of speaker groups
- Online Clustering: Assigns labels in real-time as audio chunks arrive (useful for live captioning)
The output is a timeline: “Speaker 1 spoke from 00:02:14 to 00:03:41, Speaker 2 from 00:03:41 to 00:05:08,” and so on.
Two Architectures
Modern diarization systems use one of two approaches:
Cascaded/Modular Systems run each stage as a separate component (VAD → embedder → clustering). These offer more control and work well for varying speaker counts and session lengths.
End-to-End Systems use a single neural network that takes raw audio and outputs speaker labels directly. These systems are easier to optimize and deploy but may have restrictions on speaker count.
Measuring Success: DER
The primary metric for diarization quality is Diarization Error Rate (DER), which measures the percentage of time in an audio recording that a speech segment is incorrectly labeled. A lower DER indicates better performance.
DER combines three types of errors:
- False alarms: Labeling non-speech as speech
- Missed detections: Failing to detect actual speech
- Speaker confusion: Misidentifying which speaker is talking
Leading systems achieve 80-95% accuracy in optimal conditions.
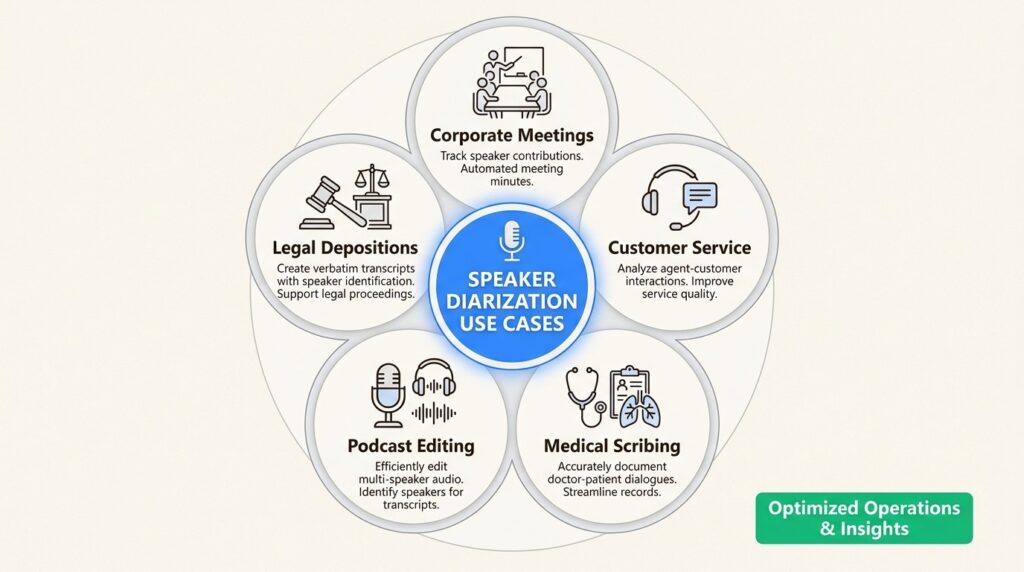
Real-World Applications
Speaker diarization isn’t just a technical curiosity. It powers critical workflows across multiple industries.
Meeting transcription and summarization
In corporate settings, meetings often involve multiple people contributing ideas, sharing updates, and making decisions. Diarization separates speaker voices, making transcriptions clearer and summaries more meaningful. Team members can see who said what, automatically generate action items per speaker, and easily review discussions for absent participants.
Contact center analytics
Customer service calls typically involve two speakers: the agent and the customer. Diarization helps monitor conversations, measuring agent performance, customer satisfaction, and service issues by separating who is talking.
Healthcare documentation
In medical settings, diarization separates doctor and patient voices for clinical documentation. This enables automated medical scribing, where the system generates structured notes with clear attribution between physician observations and patient responses.
For healthcare applications, accuracy and compliance are paramount. Systems must handle medical terminology correctly while maintaining HIPAA compliance for patient data protection. Learn more about our healthcare-focused solutions.
Media and podcast production
News broadcasts, interviews, and podcasts involve multiple speakers. Diarization automatically labels and separates speech segments for archiving, searching, subtitling, or content moderation.
Legal and compliance
Depositions, courtroom proceedings, and compliance recordings require accurate speaker attribution. Diarization creates speaker-indexed transcripts where attorneys can instantly locate all testimony from specific witnesses or verify who made particular statements.
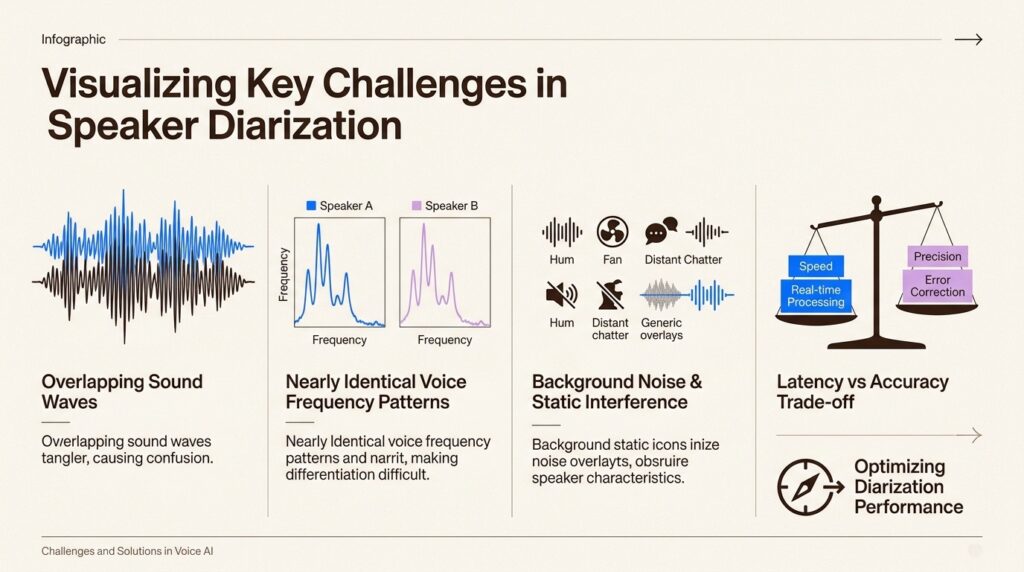
Key challenges and limitations
No diarization system is perfect. Understanding where these systems struggle helps set realistic expectations and inform recording setup decisions.
Overlapping speech
When multiple speakers talk simultaneously, diarization accuracy drops significantly. The system must separate intertwined audio streams, a problem that remains challenging even for advanced neural approaches.
Similar-sounding voices
Two people with very similar vocal qualities (same pitch range, same speaking cadence, similar accents) are harder to separate than two people who sound distinctly different. A baritone host interviewing a high-pitched guest is an easier diarization problem than two guests with similar regional accents.
Background noise and audio quality
Background noise, reverberation, and poor recording quality all degrade diarization performance. Non-speech sounds can mask or distort speaker voices, leading to identification errors.
Unknown speaker count
Diarization systems must automatically detect how many different speakers appear in a recording. This estimation becomes harder with larger groups and more variable voice characteristics.
Real-time constraints
Online clustering (processing audio as it arrives) cannot go back in time to correct mistakes. This creates a fundamental trade-off between latency and accuracy. Offline clustering (processing complete recordings) typically achieves better results but cannot support live applications.
Language and accent variations
Most diarization systems are trained primarily on English and major European languages. Performance varies significantly for Indic languages, tonal languages, and heavily accented speech. This is a key consideration for global deployments.
Choosing a Speaker Diarization Solution
If you’re evaluating diarization capabilities for your application, consider these factors:
Integration approach
- Dedicated diarization APIs: Separate service that processes audio files
- Speech-to-text with built-in diarization: Single API call returns transcribed text with speaker labels
- Pre-built transcription tools: End-to-end solutions with diarization included
The right choice depends on your existing infrastructure and whether you need diarization alone or as part of a complete transcription pipeline.
Key evaluation criteria
Accuracy and DER performance: Request benchmark results on datasets similar to your use case. Ask specifically about performance with overlapping speech and your target speaker count.
Language support: Verify support for your target languages. If you need Indic language support, confirm the system handles code-switching (speakers alternating between languages) effectively.
Real-time vs. batch processing: Determine whether you need streaming diarization for live applications or can process completed recordings.
Security and compliance: For sensitive applications (healthcare, legal, financial), verify SOC 2, HIPAA, and ISO 27001 certifications. Understand data handling practices and retention policies.
Deployment flexibility: Consider whether you need cloud-only processing or require on-premises or edge deployment for data residency requirements.
We approach diarization as part of our comprehensive Speech Intelligence suite. Our systems handle 55+ Indic languages including dialects often ignored by global providers (Awadhi, Bhojpuri, Haryanvi). We offer flexible deployment options (cloud, edge, or on-premises) with enterprise-grade security certifications including SOC 2 Type II and HIPAA compliance. For real-time applications, our streaming ASR achieves sub-250ms latency while maintaining accurate speaker attribution.
Getting Started With Speaker Diarization
If you’re considering adding diarization to your application, start here:
- Define your use case: Meeting transcription, contact center analytics, medical documentation, or media processing each have different accuracy requirements and latency constraints.
- Evaluate your audio quality: Clean recordings with distinct speakers yield better results. If your audio has significant background noise or overlapping speech, set accuracy expectations accordingly.
- Test with representative data: Run evaluations on audio that matches your production environment. Benchmark DER on your actual recordings, not just marketing materials.
- Consider the full pipeline: Diarization is one component of a speech processing system. Consider how it integrates with transcription, sentiment analysis, and downstream analytics.
- Plan for edge cases: Decide how your application handles uncertain speaker attribution. Will you flag low-confidence segments for human review?
Speaker diarization transforms unusable audio transcripts into structured, searchable, actionable data. The technology has matured significantly in recent years, with modern systems achieving accuracy levels that make production deployment viable across a wide range of applications.If you’re building voice-enabled applications and need speaker diarization that handles Indic languages, meets enterprise security requirements, and deploys on your terms, explore our Speech Intelligence features. Shunya Labs provides the complete stack from foundation models to production-ready voice agents, with the flexibility and security that enterprise deployments demand.
Leave a Reply
You must be logged in to post a comment.