

Phone support is still one of the most critical channels in customer service. It is expensive to staff, hard to scale, and often leads to frustrating experiences for both customers and agents. Long hold times, robotic interactions, and endless repetition have become the norm.
But something is changing. Voice AI agents are experiencing a renaissance. Voice is used in 82% of all customer interactions, up from 77% just a year ago (Metrigy Customer Experience Optimization: 2025-26). The market for voice and speech recognition technology is projected to grow from $14.8 billion in 2024 to over $61 billion by 2033.
This is not just about replacing phone trees with slightly better automation. Modern voice AI agents can understand natural speech, process meaning, and respond conversationally. They can handle complex workflows, integrate with business systems, and hand off to humans when needed.
In this guide, we will break down exactly how voice AI agents work, from the moment a caller speaks to the moment the agent responds. We will explore the architecture, the use cases, and the business value. And we will look at what it takes to build voice AI that actually works in production.
What Is a Voice AI Agent?
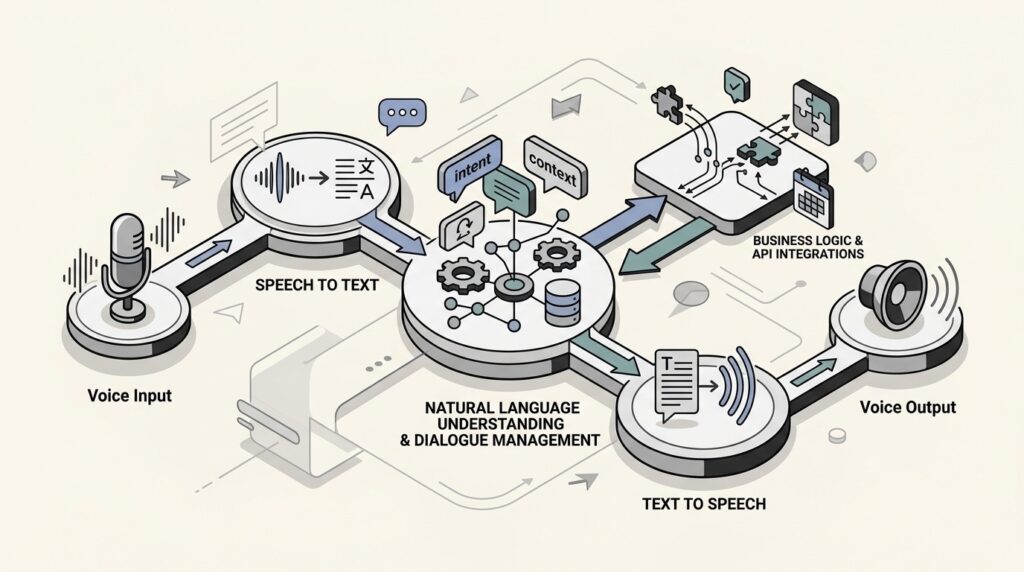
A voice AI agent is an intelligent, speech-driven system that can understand natural language, determine intent with context, and complete tasks in real time. Think of it as a skilled receptionist that never misses a call, responds instantly, and maintains full awareness of the conversation.
Unlike traditional interactive voice response (IVR) systems that force callers through rigid menu trees (“Press 1 for sales, Press 2 for support”), voice AI agents understand natural speech. A caller can say “I need to reschedule my appointment” or “My order never arrived” and the agent understands what they want.
Here is what a voice AI agent can do:
- Interpret caller requests expressed in natural language, identifying whether the person is trying to reschedule an appointment, ask a question, or escalate an issue
- Access business systems required to complete the task, including calendars, CRM platforms, electronic health records, or billing tools
- Carry out operational tasks from start to finish, such as booking appointments, qualifying leads, or checking policy details
- Route callers based on true conversational intent, sending them directly to the right team member instead of forcing them through menu-based navigation
- Document every interaction as structured data, capturing intent, sentiment, outcomes, and follow-up requirements
The leap in capability reflects a broader shift in customer engagement. Voice is not going away. In fact, it is becoming more essential as businesses realize that phone interactions remain the preferred channel for urgent, complex, or critical issues.
The Core Architecture: How Voice AI Works End to End
From the caller’s perspective, the interaction is simple: they speak, and the agent responds. Behind that simplicity is a layered process that blends multiple technologies into a seamless pipeline.
Let’s break down the core architecture that makes this possible.
Speech Recognition (ASR)
Every voice interaction starts with automatic speech recognition (ASR). This component converts spoken audio into text that the system can process.
Modern ASR systems have come a long way from the rigid voice recognition of the past. Today’s systems can:
- Transcribe different accents and speech patterns at high accuracy (top systems achieve word error rates as low as 3.1%)
- Handle background noise and challenging audio environments
- Process speech in real time with minimal delay
- Support multiple languages and even detect language switches mid-conversation
The quality of your ASR layer directly impacts everything downstream. A 95% accurate system produces 5 errors per 100 words. An 85% accurate system produces 15 errors per 100 words. That difference determines whether your voice AI feels helpful or frustrating.
Language Understanding (LLM)
Once speech becomes text, a large language model (LLM) figures out what the user actually wants. This goes far beyond simple keyword matching.
The LLM handles:
- Intent detection: Determining whether the caller wants to book an appointment, check an order status, or file a complaint
- Entity extraction: Pulling out specific details like dates, names, order numbers, or policy types
- Context management: Remembering information shared earlier in the conversation so callers do not have to repeat themselves
- Reasoning: Working through complex requests that require multiple pieces of information or conditional logic
This is where modern voice AI diverges from older systems. Traditional IVR could only handle rigid commands. Today’s LLM-powered agents can follow complex conversations, remember context from earlier exchanges, and respond to interruptions or changes in topic.
Text-to-Speech (TTS)
The final component transforms the agent’s text response back into spoken words. Text-to-speech technology has evolved to create voices that capture natural rhythm, emphasis, and emotion.
Advanced TTS systems can:
- Match tone to the emotional state of the conversation
- Use appropriate pacing and pauses for clarity
- Pronounce industry-specific terminology correctly
- Switch voices or languages mid-conversation when needed
The goal is not just to sound human, but to sound appropriate for the context. A healthcare voice agent should sound calm and reassuring. A sales agent might be more upbeat and energetic.
The Orchestration Layer
Beyond the core speech components, a production voice AI needs an orchestration layer that manages the conversation flow. This layer:
- Chooses the best resolution path based on intent
- Connects to business systems via APIs (CRM, ticketing, scheduling, billing)
- Handles error recovery when something goes wrong
- Decides when to escalate to a human agent
- Maintains conversation state across multiple turns
Without solid orchestration, even the best speech recognition and language models produce disjointed, frustrating experiences.
Latency Requirements
One factor that binds all these components together is latency. For a conversation to feel natural, the agent must respond within 250 milliseconds. Anything longer creates awkward pauses that break the conversational flow.
Achieving sub-250ms latency requires careful optimization across the entire pipeline: fast ASR, efficient LLM inference, streaming TTS, and minimal network overhead.
Three Architectural Approaches Compared
While the cascading model (ASR → LLM → TTS) is common, it is not the only way to build a voice agent. The architecture you choose impacts everything from latency to conversational flexibility.
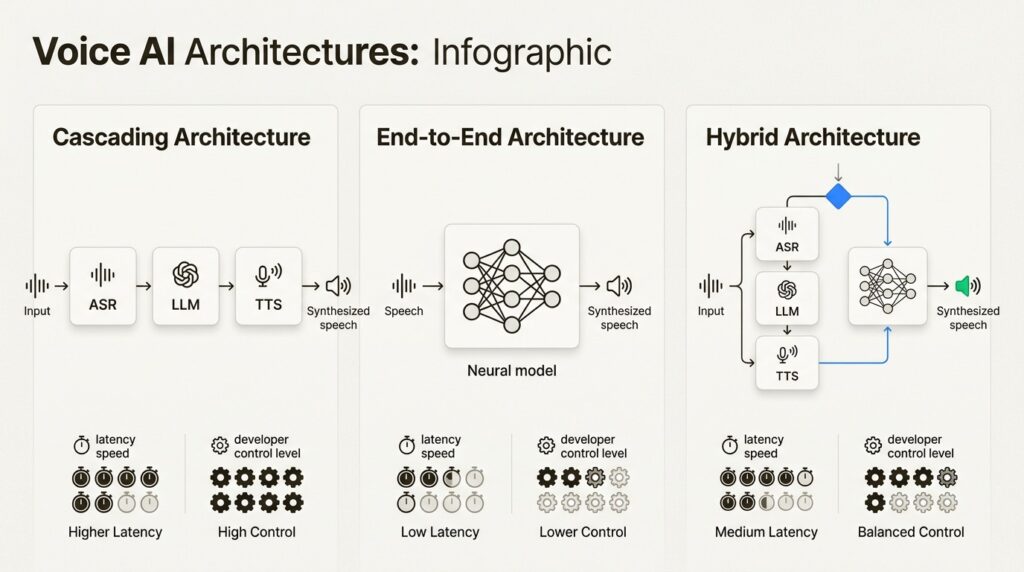
Cascading Architecture
The traditional approach uses a series of independent models: speech-to-text, then a language model for understanding, then text-to-speech for the response.
Strengths:
- Modular and easier to debug
- High control and transparency at each step
- Robust function calling and structured interactions
- Reliable, predictable responses
Best for: Structured workflows, customer support scenarios, sales and inbound triage
Trade-offs: The handoffs between components can add latency, sometimes making conversations feel slightly delayed.
End-to-End Architecture
This newer approach uses a single, unified AI model to handle the entire process from incoming audio to spoken response. OpenAI’s Realtime API with gpt-4o-realtime-preview is an example of this approach.
Strengths:
- Lower latency interactions
- Rich multimodal understanding (audio and text simultaneously)
- Natural, fluid conversational flow
- Captures nuances like tone and hesitation better than cascading systems
Best for: Interactive and unstructured conversations, language tutoring, conversational search and discovery
Trade-offs: More complex to build and fine-tune. Less transparent since you cannot inspect the intermediate text representations.
Hybrid Architecture
A hybrid approach combines the best of both worlds. It might use a cascading system for its robust, predictable logic but switch to an end-to-end model for more fluid, open-ended parts of a conversation.
Strengths:
- Optimizes for both performance and capability
- Can use cascading for structured tasks and end-to-end for natural conversation
- More flexible than either pure approach
Best for: Complex applications that need both reliability and conversational flexibility
| Architecture | Latency | Control | Best For |
|---|---|---|---|
| Cascading | Higher | High | Structured workflows, support |
| End-to-End | Lower | Medium | Fluid conversations, tutoring |
| Hybrid | Medium | High | Complex, multi-modal applications |
Real-World Use Cases and Applications
Voice AI agents have moved beyond novelty to become practical business tools across every industry. Here are the key applications delivering measurable results.
Customer Support Automation
The most common use case is handling tier-1 support calls without wait times. Voice AI agents can:
- Answer common questions using knowledge base articles
- Troubleshoot basic issues through guided conversations
- Process returns, refunds, and account changes
- Create and update support tickets with full context
- Escalate complex issues to human agents with conversation summaries
In some implementations, AI agents now manage as much as 77% of level 1 and level 2 client support.
Appointment Scheduling
Healthcare clinics, salons, and service businesses use voice AI to handle scheduling without staff involvement:
- Book appointments across multi-provider calendars
- Handle rescheduling and cancellations
- Send reminders and confirmations
- Collect pre-visit information
- Route urgent requests to appropriate staff
Sales and Lead Qualification
For sales organizations, inbound voice interactions are often time-sensitive. Voice AI agents can:
- Ask predefined questions to qualify leads
- Route qualified leads to the appropriate sales team
- Capture key information for follow-ups
- Log call summaries into connected CRM systems
- Provide 24/7 coverage for after-hours inquiries
Healthcare Coordination
Healthcare organizations have specific requirements around compliance and accuracy. Voice AI agents in healthcare can:
- Manage appointment scheduling and reminders
- Conduct pre-visit questionnaires
- Provide medication reminders
- Route urgent medical concerns to appropriate staff
- Maintain HIPAA compliance throughout interactions
Internal Operations
Voice AI is not just for customer-facing use cases. Internal applications include:
- Hands-free access to manuals and documentation for field technicians
- Inventory management and parts ordering
- Time tracking and work logging
- Equipment status checks
- Safety reporting
Business Benefits and ROI
The business case for voice AI agents goes beyond cost reduction. When implemented correctly, they transform operations across multiple dimensions.
Operational Efficiency
Voice AI agents deliver three key operational advantages:
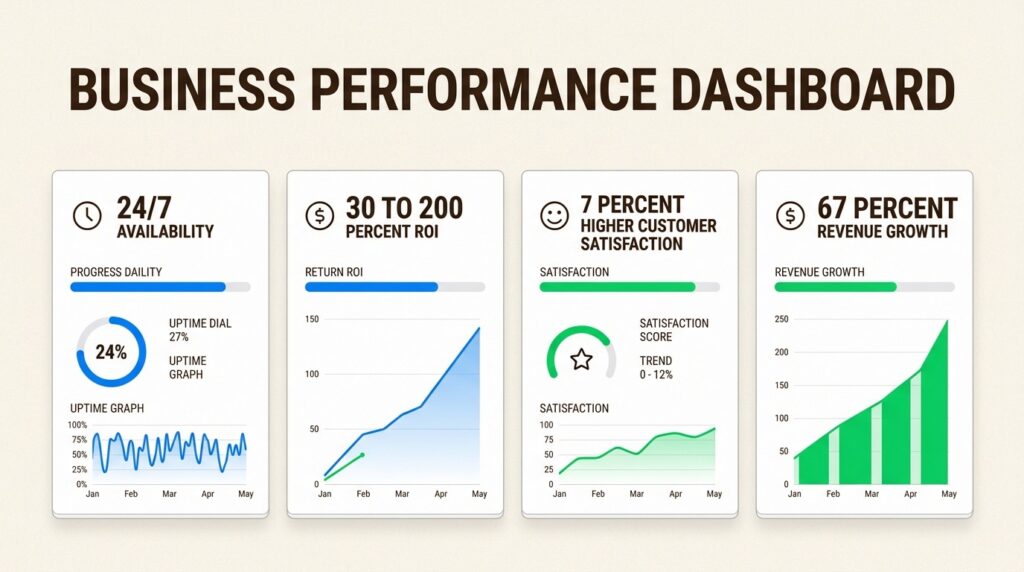
- 24/7 availability: Provide instant support to customers in any time zone without increasing headcount
- Reduced handling time: Automate data collection and initial troubleshooting to resolve issues faster
- Lower operational costs: Decrease reliance on large contact center teams for routine support
Businesses implementing automation see ROI improvements ranging from 30% to 200% in the first year.
Customer Experience
Long wait times and inconsistent service are major sources of customer frustration. Voice AI agents address these pain points directly:
- No more wait times: Instantly answer incoming calls, eliminating frustrating queues
- Consistent information: Ensure every customer receives standardized, correct information pulled directly from your knowledge base
- Personalized interactions: Use data from your CRM to greet customers by name and understand their history
Automating workflows can improve customer satisfaction by nearly 7%.
Business Scalability
As your business grows, so does the volume of customer interactions. Voice agents provide a scalable solution:
- Handle thousands of concurrent calls without performance drops
- Expand your customer base without linear increases in support staff costs
- Manage seasonal spikes and unexpected volume surges
- Enter new markets with 24/7 coverage from day one
67% of telecom businesses using automation report revenue increases.
Data and Insights
Unlike human agents who may forget to document calls, voice AI agents automatically record and categorize every conversation:
- Structured data on intent, sentiment, and outcomes
- Analytics for identifying trends and improvement opportunities
- Quality monitoring without manual review
- Training data for continuous improvement
Key Challenges and Considerations
Voice AI agents are powerful, but they are not magic. Building systems that work in production requires addressing several key challenges.
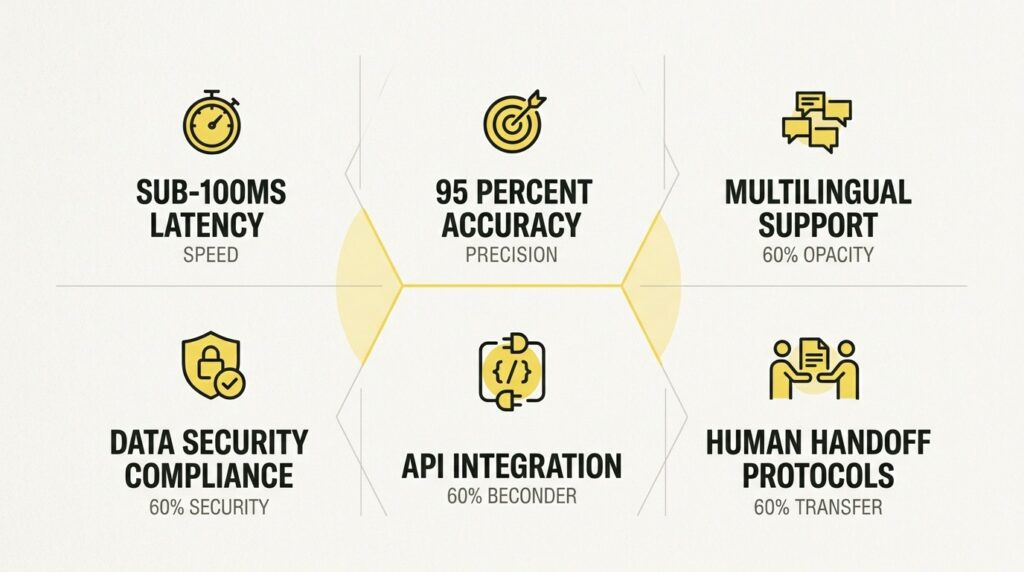
Latency
For a conversation to feel natural, the agent’s response time must be near-instantaneous. High latency leads to awkward pauses and a frustrating user experience. Look for platforms optimized for real-time streaming transcription and low-latency responses.
Accuracy
The difference between an 85% accurate system and a 95% accurate one is significant. It can mean reducing transcription errors from 15 per 100 words to just five. Test any platform with your own audio data, including accents, background noise, and industry-specific terminology.
Multilingual Support
If you serve diverse populations, language support is critical. This includes not just multiple languages, but:
- Accent and dialect variations
- Codeswitching (mixing languages mid-sentence)
- Regional terminology and expressions
- Language detection and automatic switching
Most platforms claim multilingual support, but quality varies significantly across languages.
Security and Compliance
Voice interactions often involve sensitive information. Key considerations include:
- Data encryption: Both in transit (TLS) and at rest (AES-256)
- Compliance certifications: SOC 2 Type II, ISO 27001, HIPAA for healthcare
- Consent management: Recording and data usage disclosures
- Data residency: Where voice data is stored and processed
- Retention policies: How long recordings are kept and how they are deleted
The 2024 FCC ruling affirmed that AI-generated voices are considered “an artificial or pre-recorded voice” under the Telephone Consumer Protection Act (TCPA), making consent rules apply to voice AI agents.
Integration Complexity
Voice AI agents rarely operate in isolation. You will need to connect to:
- CRM systems
- Ticketing platforms
- Scheduling systems
- Billing and payment systems
- Internal databases and APIs
The complexity of these integrations often determines how much value you can actually extract from voice AI.
Human Handoff
Even the best voice AI agents cannot handle everything. You need clear escalation paths:
- When should the agent transfer to a human?
- What context should be passed along?
- How do you handle the transition smoothly?
- What happens if no human is available?
Getting handoff right is often the difference between a voice AI that helps customers and one that frustrates them.
Building Voice AI on Your Terms
At Shunya Labs, we have spent years solving the fundamental problems that make voice AI expensive, slow, and insecure. Our approach differs from generic API providers in several key ways.
Foundation Models Built for Voice
Rather than stitching together third-party APIs, Shunya Labs have built our own foundation models specifically for voice:
- Zero STT: General-purpose transcription supporting 200+ languages
- Zero STT Indic: Specialized for superior accuracy in Indian languages
- Zero STT Codeswitch: Native model for multilingual speech mixing
- Zero STT Med: Domain-specific recognition for medical terminology
This matters because speech recognition quality varies dramatically by language and domain. A model trained primarily on English will struggle with Indic languages. A general-purpose model will miss medical terminology. Our specialized models address these gaps.
Deployment Flexibility
Not every organization can send voice data to the cloud. Shunya Labs offer deployment options that match your security and latency requirements:
- Cloud API: Fully managed, scales automatically
- Local Deployment: Run on your own infrastructure
- On-Premises/Edge: For strict data sovereignty or ultra-low latency requirements
We maintain SOC 2 Type II, ISO 27001, and HIPAA compliance.
Deep Regional Expertise
Our roots in the Indic languages have given us unique capabilities:
- Support for 55+ Indic languages with more in development
- Native handling of codeswitching (Hinglish, Tanglish, etc.)
- Understanding of regional accents and dialects
- Cultural context for conversational AI
Frequently Asked Questions
How does a voice AI agent differ from a traditional IVR system?
A traditional IVR forces callers through rigid menu trees. A voice AI agent understands natural speech, can handle complex conversations, remembers context from earlier exchanges, and responds to interruptions or changes in topic. It can also integrate with business systems to complete tasks end-to-end rather than just routing calls.
What is a voice AI agent’s typical response time?
For natural conversation, voice AI agents need to respond within 250 milliseconds. Anything longer creates awkward pauses. Achieving this requires optimization across speech recognition, language model inference, and text-to-speech generation.
Can a voice AI agent handle multiple languages in one conversation?
Advanced voice AI agents can handle codeswitching, where callers mix languages mid-sentence (like Hinglish or Spanglish). This requires specialized models trained on multilingual speech patterns, not just separate language models stitched together.
What compliance requirements apply to voice AI agents?
Voice AI agents must comply with regulations like the Telephone Consumer Protection Act (TCPA) in the U.S., which requires consent for automated calls. For healthcare applications, HIPAA compliance is mandatory. Look for providers with SOC 2 Type II and ISO 27001 certifications.
How do voice AI agents integrate with existing business systems?
Modern voice AI agents connect to CRM platforms, ticketing systems, scheduling tools, and internal databases via APIs. The orchestration layer handles these integrations, allowing the agent to look up customer data, create tickets, book appointments, and trigger workflows during live conversations.
When should a voice AI agent transfer to a human?
Voice AI agents should escalate when they detect complex issues beyond their training, emotional distress or frustration from the caller, requests requiring human judgment or empathy, or technical failures. The best implementations pass full conversation context to the human agent so callers do not have to repeat themselves.

