

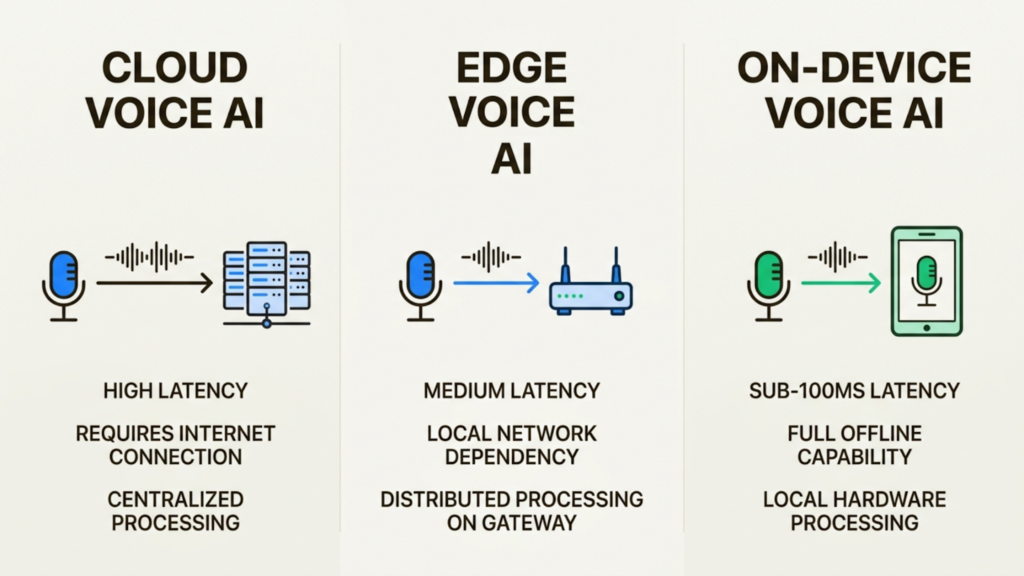
Voice AI has traditionally lived in the cloud. You speak, your audio travels to a data center, gets processed, and the response comes back. That round trip takes time. It also creates privacy concerns and requires constant connectivity.
On-device voice AI deployment changes this model entirely. The processing happens locally on your device, whether that is a smartphone, an embedded system, or an edge server. The data never leaves, the response is nearly instant, and the system works even without the internet.
In this guide, we will explain what on-device voice AI deployment means, why enterprises are adopting it, and how it compares to cloud-based alternatives.
What Is On-Device Voice AI Deployment?
On-device voice AI deployment means running speech recognition, language understanding, and speech synthesis directly on local hardware rather than remote servers. Your voice data stays on the device throughout the entire pipeline.
The typical pipeline looks like this: voice activity detection identifies when someone is speaking, speech-to-text converts the audio to text, a language model processes the meaning, and text-to-speech generates the response. In an on-device deployment, all of these steps happen locally.
This is different from edge deployment, where processing happens on a nearby server or gateway, and cloud deployment, where audio travels to distant data centers. On-device is the most private and lowest-latency option because data never leaves the hardware it was captured on.
The shift toward on-device processing is happening because of specialized neural processing units in consumer hardware, the development of smaller and more efficient AI models, and growing enterprise requirements for data privacy and compliance.
Why Enterprises Are Moving Voice AI To The Edge
The move toward on-device and edge deployment is not just about technology. It addresses specific operational requirements that matter to businesses.
Latency that feels instant
Cloud round trips add delay. Even fast connections introduce 100-300 milliseconds of latency, and complex multi-model systems compound this. For real-time applications like voice agents in contact centers, every millisecond matters.
On-device processing eliminates network round trips entirely. Leading solutions achieve sub-1000ms response times. At Shunya Labs, our streaming ASR operates under 100ms for real-time applications. This makes conversations feel natural rather than robotic.
Privacy by design
When voice data leaves the device, it creates exposure. GDPR, HIPAA, and other regulations require strict controls over personal data. Healthcare organizations cannot send patient conversations to third-party clouds. Financial services face similar constraints.
On-device processing keeps data local by default. It never traverses networks or sits on external servers. This makes compliance simpler and reduces the attack surface for data breaches.
Reliability in any environment
Cloud-dependent systems fail when connectivity drops. This is unacceptable for mission-critical applications like in-vehicle voice commands, field operations in remote areas, or industrial IoT sensors.
Edge and on-device deployments operate independently of network conditions. They process and store data locally, syncing when connectivity returns. This ensures continuity in harsh or disconnected environments.
Cost efficiency at scale
Streaming high-resolution audio from thousands of devices generates significant bandwidth and cloud infrastructure costs. On-device processing eliminates these recurring expenses, making large-scale deployments economically viable.
Technical Approaches For Edge Optimization
Running AI on resource-constrained devices requires specialized techniques. Raw models designed for cloud data centers are too large and slow for edge hardware.
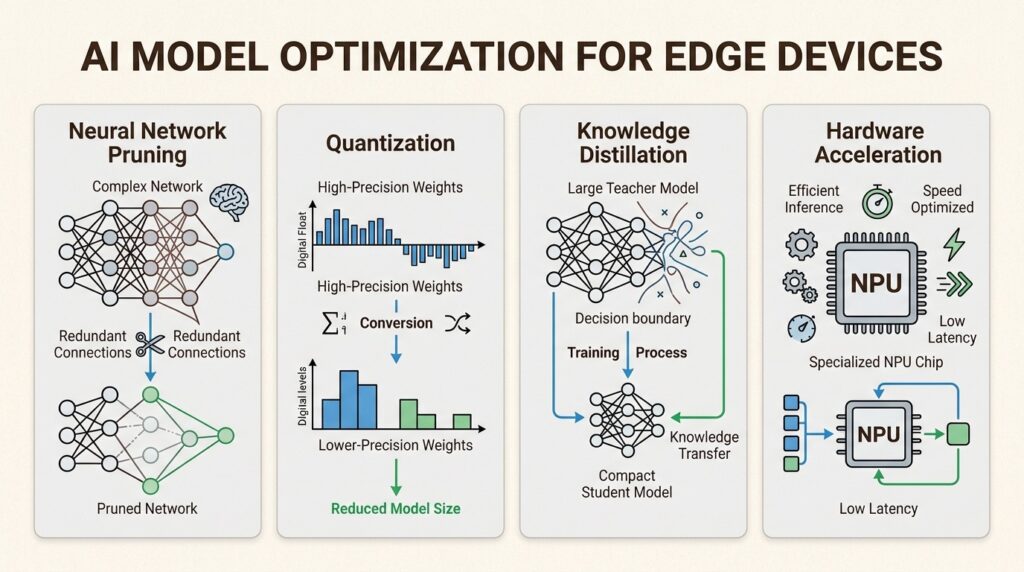
Model compression
Compression reduces model size so it fits within limited memory. Techniques include pruning, which removes redundant neurons or weights, and quantization, which converts models from 32-bit floating point to 8-bit or lower precision.
These techniques can shrink models by 50-90% while maintaining acceptable accuracy. A voice assistant on a smart speaker can answer quickly because the model is small enough to run locally.
Knowledge distillation
Distillation trains a small model to mimic a larger, more complex one. The smaller student model learns from the larger teacher model, keeping accuracy high while using fewer resources.
This approach works well for conversational applications where you need quality responses without cloud dependency.
Frameworks and hardware acceleration
Developers use TensorFlow Lite, ONNX Runtime, CoreML, and OpenVINO to deploy models across platforms. Modern hardware includes neural processing units like the Apple Neural Engine, Qualcomm Hexagon, and Google Tensor cores that accelerate inference.
The multi-language challenge
Supporting 200+ languages on edge devices is technically demanding. Each language requires acoustic and linguistic models, and combining them increases memory requirements. Code-switching, where speakers alternate between languages mid-sentence, adds additional complexity.
Most edge voice AI solutions prioritize major languages like English, Spanish, and Mandarin. Support for Indic languages and mixed-language conversations remains limited.
Real-World Use Cases For On-Device Voice AI
The applications for edge voice AI span industries and use cases.
Contact centers
Real-time agent assistance requires sub-100ms latency to avoid interrupting natural conversation flow. On-device processing provides immediate transcription and suggestion generation without sending sensitive customer data to external servers.
Healthcare
Clinical documentation must comply with HIPAA and other regulations. On-device speech recognition lets clinicians dictate notes without exposing patient information to cloud services. Our model is specifically optimized for medical terminology and clinical workflows.
Automotive
Voice commands for navigation, climate control, and entertainment should work in tunnels, remote highways, or areas with poor cellular coverage. Edge processing ensures functionality regardless of connectivity.
IoT and smart devices
Smart speakers, appliances, and industrial sensors benefit from local voice control. Commands execute instantly without cloud dependency, and privacy concerns are minimized.
Field operations
Workers in mining, agriculture, and construction often operate in areas without reliable connectivity. On-device voice interfaces let them interact with systems, log data, and receive instructions without needing network access.
How Shunya Labs Approaches Voice AI
Most voice AI providers focus on cloud deployment. Those offering edge options typically support a limited language set, often centered on English and major European languages. This leaves significant gaps for global enterprises.
We built our Zero STT Suite specifically for deployment flexibility and multilingual support.
The Zero STT Suite
Our foundation models cover the full range of speech recognition needs:
| Model | Purpose | Key Features |
|---|---|---|
| Zero STT | General-purpose STT | 200+ languages, streaming support |
| Zero STT Indic | Indian languages | 32+ Indic languages, regional accents |
| Zero STT Codeswitch | Mixed-language speech | Native code-switching support |
| Zero STT Med | Healthcare | HIPAA-compliant, medical terminology |
Language coverage that matches the real world
We support 200+ languages including 32+ Indic languages. This is not just about translation. Our models understand regional accents, dialects, and the way people actually speak, including code-switching between languages.
For example, our Zero STT Codeswitch model handles Hinglish (Hindi + English), and other common language pairs natively. This is critical for markets like India, where mixed-language speech is the norm rather than the exception.
Flexible deployment options
We offer three deployment modes to match your requirements:
| Deployment | Best For | Data Handling |
|---|---|---|
| Cloud API | Rapid prototyping, variable workloads | Processed in our SOC 2 Type II certified infrastructure |
| Edge | Low-latency requirements, bandwidth constraints | Processed on your edge hardware |
| Self-hosted/On-premises | Strictest compliance, air-gapped environments | Fully contained within your infrastructure |
Enterprise-grade security
Our platform maintains certifications that enterprises require. We are SOC 2 Type II certified, ISO/IEC 27001:2022 accredited, and HIPAA compliant. Our two-sided encryption uses both TLS and AES-256 to protect data at rest and in transit.
Deploy Voice AI On Your Terms With Shunya Labs
On-device voice AI deployment is moving from niche applications to mainstream enterprise infrastructure. The benefits are clear: sub-100ms latency, enhanced privacy, offline operation, and reduced bandwidth costs.
The challenge has been finding solutions that support the languages your users actually speak. Most edge voice AI is built for English-first markets. If your users speak Hindi, Tamil, Bengali, or switch between languages mid-sentence, you may have been poorly served by the market.
We built Shunya Labs to solve this. Whether you need cloud API access for rapid development, edge deployment for latency-sensitive applications, or full on-premises installation for compliance, we have you covered.If you are evaluating voice AI for contact centers, healthcare, automotive, or IoT applications, contact us here. Our team can assess your requirements and recommend the right deployment architecture for your use case.