Actual hospitals are inundated with alarms, cross-talk, muffled conversations through surgical masks and contextual shorthands that can generally be understood only by highly specialized participants.
The urgent directions echoing through the floors require fast execution by specific stakeholders, for which it is necessary that the intended recipients can recognize that they are being addressed, comprehend what’s being shared and respond accordingly.
Generic ASR systems are not trained to identify the subtle distinction between near-homophones in medical conditions or prescriptions with Latinate names.
This is why we built our domain-specific model for healthcare, Zero STT Med, which has attained exceptional accuracy and real time transcription speed across medical environments, while offering enterprise-grade privacy and compliance for healthcare settings.
Why domain specialisation really matters in medical speech transcription
Generic ASR systems are generally effective at decoding casual speech. But clinical speech is another matter: near-homophones abound, drug names and specialty jargon are plentiful, and abbreviations vary by department.
Domain-specific medical speech-to-text models are trained on medical data, terminology, and concepts so they can stay reliable inside this reality—not just on clean, conversational demos.
To make this concrete, here are a few examples where a small transcription error can have a very large impact.
Near-homophone drug names with very different uses
| Example pair | What each is used for | Why confusion is dangerous |
|---|---|---|
| Celebrex(celecoxib) vs Celexa(citalopram) | Celebrex: anti-inflammatory for pain/arthritis. Celexa: SSRI antidepressant. | The wrong drug can mean uncontrolled pain or undertreated depression, plus withdrawal risk if antidepressant doses are missed. |
| Hydralazine vs Hydroxyzine | Hydralazine: vasodilator for hypertension/heart failure. Hydroxyzine: antihistamine used for itching, allergy, or anxiety. | Mixing these up can leave blood pressure uncontrolled or give unnecessary sedation instead of cardiovascular treatment. |
| Zantac(ranitidine) vs Xanax(alprazolam) | Zantac: acid-suppressing drug (H₂ blocker; no longer widely marketed in many regions). Xanax: benzodiazepine for anxiety. | Confusion can lead to missed anxiety management, unexpected sedation, or inappropriate long-term benzodiazepine exposure. |
These are exactly the kinds of look-alike / sound-alike (“LASA”) pairs flagged in medication safety literature and ISMP/FDA tall-man lettering lists.
Abbreviations that shift meaning with speciality and context
| Abbreviation | Possible meanings (by context) | Why this is risky |
|---|---|---|
| MI | Most commonly myocardial infarction (“heart attack”). Historically also used for mitral insufficiency/ mitral incompetence in some contexts. | If a system (or reader) assumes the wrong expansion, care teams can misinterpret whether the issue is coronary ischemia or valve disease. |
| RA | Rheumatoid arthritis, right atrium, or room air, among others. | “RA” in a cardiology note vs a rheumatology note vs a respiratory observation can mean very different things; misreading it flips the clinical picture. |
| MS | Multiple sclerosis, mitral stenosis, or morphine sulfate(the latter now discouraged as an abbreviation). | Confusing a chronic neurologic disease, a valve lesion, and a high-risk opioid dose can radically change diagnosis, treatment, and safety decisions. |
| CP | Chest pain in many ED/ICU notes vs cerebral palsyin neurology or rehab contexts. | In triage notes, “CP” usually points to possible cardiac ischemia; in pediatrics it often refers to a lifelong neurodevelopmental condition. Context is everything. |
This is very important because the cost of mishearing is too high in healthcare. In other domains, a mistaken word may be annoying; in medicine, a confident wrong word is a matter of life and death.
If you mishear a drug name, it can change the entire treatment plan for the patient. A missed negation (“no chest pain”) reverses the interpretation of a symptom. Attributing a statement to the wrong speaker changes who is responsible for a decision in the chain of care. Domain-specialised medical ASR exists to reduce exactly these kinds of errors.
Shunya Labs’ research that powers ASR designed for real clinical complexity
Rather than blindly increasing dataset sizes under the banner of AI at scale, we prioritized curated, information-rich clinical audio, enabling the model to develop robust performance capabilities in uncertain scenarios.
Zero STT Med is trained with a deliberate emphasis on challenging, high-entropy conditions:
- Acoustic environment: alarms, ventilators, reverberation, masked speech, poor microphone quality, laptop microphones, simultaneous speakers.
- Audio variety: local pronunciations, dialect changes, infrequent phoneme sequences, in-sentence code-mixing.
- Language diversity: specialty terminology, similar drug names, abbreviations, and unconventional expressions within various departments.
- Situational ambiguity: multi-morbid histories, complaints changing on the same visit, and acronyms that only seem to clarify in relation to symptoms, medications, vitals, and specialty context.
Clinical audio is not simple: emergency consults over alarms; OR chatter through masks; ICU handoffs with ventilator audio; telehealth visits on everyday devices with family members stepping in mid-call. A good system must distinguish speakers, track turns, and be consistent in this environment, not just in a quiet laboratory setting.
Conventional methods that rely on fixed custom vocabularies, specialty packs, and frequent retraining are ultimately fragile and costly. We instead focus on getting the base model right: training directly on messy, multilingual, multi-speaker clinical audio so it naturally learns to handle the ambiguity and shifting medical language it will encounter in context, rather than a long list of manual exceptions.
That is why we built Zero STT Med to stay accurate over time, even as new drug names, workflows, and clinical realities change over time.
Medical transcription that understands clinical terminology
Zero STT Med is not only designed to “hear” speech clearly; it is also designed to recognise when something is clinically important. In addition to getting the audio right, Zero STT Med is able to identify clinical terms, and therefore, to get them right in transcription.
Our model can reliably transcribe:
- Medications and drugs – brand and generic names, including look-alike/ sound-alike pairs.
- Diagnoses – primary problems, differentials, and comorbidities, even when they appear in long, conversational dictations.
- Anatomical terms – body parts, regions, and structures as they are actually described in imaging, consults, and operative reports.
- Procedures and interventions – surgeries, imaging studies, bedside procedures, and therapies mentioned in passing or as part of a longer plan.
- Labs, measurements, and units – numbers, ranges, and units captured together so values remain clinically meaningful.
- Clinical shorthand and acronyms – abbreviations whose meaning depends on specialty and context, resolved using the surrounding note rather than a fixed glossary.
This generates more accurate outcomes that clinicians can rely on, and in turn makes them more reliable for downstream systems like the EHR, coding workflows, and decision-support tools.
Accurate where it matters the most—getting medical terms right
When we discuss accuracy for Zero STT Med, our primary concern is whether transcriptions can stay accurate on medical data.
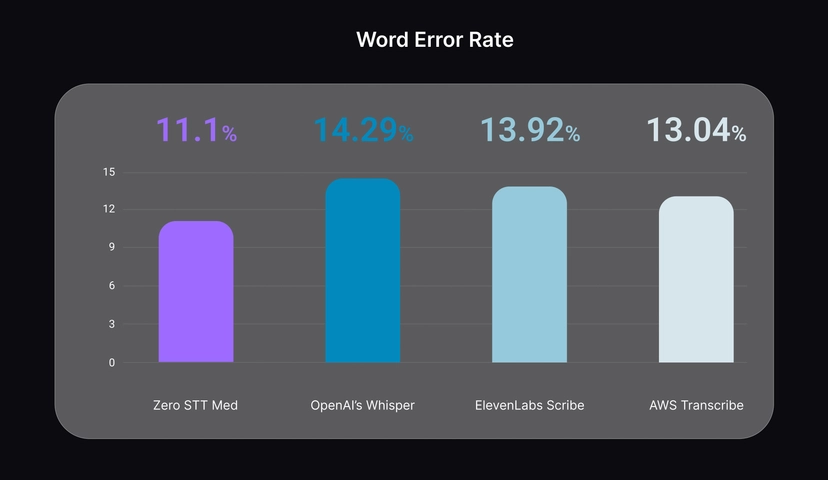
On medical speech benchmarks with noisy, multi-speaker clinical audio, Zero STT Med reaches:
- 11.1% Word Error Rate (WER)
- 5.1% Character Error Rate (CER)
outperforming ASR systems like OpenAI Whisper, ElevenLabs Scribe, and AWS Transcribe in such assessments.
The outcome is a transcript that clinicians spend less time on correcting drug names, conditions, and negations, so they can solely focus on patient care quality.
See how our model performs on your own cases in our Zero STT Med medical speech-to-text demo widget.
Low latency real-time transcription for clinical conversations with multiple speakers
In clinical settings, latency is more than a technical parameter—it directly shapes how people experience and adopt the tool.
- Emergency consults are fast-paced and noisy.
- OR and ICU communication happens through masks and around equipment.
- Telehealth visits run on everyday hardware, with interruptions and multiple speakers.
When the transcript is lagging behind the discussion, individuals tend to restate points, decelerate their speech unnaturally, or cease utilizing the system altogether. Slow transcription also mute the benefit of making patient care truly accessible with live captioning or translation for understanding across languages or accents.
Zero STT Med is engineered for streaming use cases so that transcription aligns with the flow of clinical conversation, even amidst environmental noise or interruptions.
Importantly this includes live speaker diarization: the system tracks who is speaking in real time (for example, doctor vs patient vs nurse) so the transcript remains structured and intelligible during the conversation.
Combined, low latency and live speaker diarization provide a truly ambient experience: notes are created during the visit itself, rather than reconstructed post hoc. Doctors have the opportunity to review, revise, and complete documentation with significantly reduced effort, maintaining attention on the patient before them.
Privacy & security: enterprise-grade compliance, on your terms
Clinical transcription requires the same level of quality as your entire clinical stack, particularly when dealing with protected health information and imagery. Zero STT Med is engineered to prioritize privacy, security and compliance as core functionalities rather than optional enhancements.
- On-prem and private cloud options: run entirely inside your hospital network, private cloud, or VPC so that patient photos, audio, and transcripts never leave your environment to be transcribed.
- Enterprise-grade compliance: designed to meet the privacy and security standards employed by hospitals and health systems globally, ensuring legal, security, and compliance teams have a straightforward process for review and approval.
- Comprehensive security measures: data encryption during transmission and storage, robust access controls, and traceable actions ensure that sensitive clinical information is securely managed at all stages.
This is how we end up with a medical speech-to-text solution that can live where the care actually happens — within your own infrastructure — and that meets the needs of clinical, IT, and compliance audiences by providing an enterprise-grade, privacy-first solution.
Ready to Deploy: Medical Transcription API Integration
That’s why we created Zero STT Med, to seamlessly integrate with the current state of hospitals and clinics. The system is operational and designed for practical application during clinical sessions.
To explore deployment and pricing, contact our team about Zero STT Med API integration.