TL;DR , Key Takeaways:
- Human conversation has a 200 to 300ms natural response window. Above 500ms, users consciously notice the lag. Above 1 second, abandonment rates climb sharply.
- Most voice agents in production today run at 800ms to 2 seconds, not because the models are slow, but because pipeline stages compound silently.
- The four latency culprits are audio buffering, STT processing, LLM inference, and TTS synthesis. Each stage can be tuned independently.
- Sub-100ms is achievable at the STT layer right now. Getting the total pipeline below 500ms is an architecture problem, not a model problem.
- On-device CPU-first STT eliminates network round-trips entirely and satisfies data residency requirements for Indian enterprise deployments.
- WebSocket over REST, streaming everywhere, right-sized LLMs, and regional or on-premise inference: these four choices close most of the gap.
There is a moment in every voice AI demo where something clicks. The agent responds quickly, the rhythm feels right, and the conversation moves forward the way a real conversation does. Then the same team ships to production, and the first thing users say is: “Why does it pause so long?”
That pause is not a model problem. Benchmarks published in late 2025 from 30-plus independent platform tests show that most voice agents in production still clock in at 800ms to two full seconds end-to-end.
The reason is pipeline compounding. Every stage in the voice agent stack adds time, and those stages run sequentially. Each handoff adds overhead. Endpointing waits for silence. Audio buffers in chunks. The LLM waits for a complete transcript. TTS waits for a complete LLM response. By the time sound reaches the user’s ear, a dozen small decisions have each added 50 to 200 milliseconds, and the total has long since crossed the threshold where conversations feel natural.
This post pulls that apart layer by layer. What are the actual numbers at each stage? Where do teams waste the most time? What does a well-architected low-latency pipeline look like in 2026? And what does it mean specifically for teams building in India, where geography adds an unavoidable physics tax on top of
200ms
Natural human response window
The gap the brain expects between turns
40%
Abandonment spike above 1 second
Contact centre data, 2025–2026 benchmarks
800ms
Typical production agent today
Despite sub-200ms component speeds
The 300ms Rule and Why It Is Not Just a User Experience Concern

Research consistently puts the natural human conversational gap at 100 to 400 milliseconds. This is not a UX preference, it is a neurological baseline. Beyond 300ms, users may not consciously register a delay. Beyond 500ms, they can consciously notice it. Beyond one second, the conversation starts to feel broken, users may speak again assuming the agent did not hear them, interruptions multiply, and abandonment rates spike. Abandonment rates climb more than 40% when latency exceeds one second.
Latency is a paralinguistic signal. When a voice agent pauses, users read that pause as meaning something uncertain, failure, machine-ness. The rhythm of a conversation can shape how its content is received.
There is also an operational cost here that is separate from user experience. Longer interactions cost more to run. More pauses can mean more false turn detections, more correction cycles, more agent time per call. A team handling 50,000 calls a day saw clean average latency metrics, but churn and complaints stayed high because their P99 latency was spiking, affecting a small but vocal slice of users consistently.
This is the case for tracking P95 and P99 metrics, not just averages. A 400ms average with 2-second P99 spikes means users are abandoning calls even though the dashboard looks fine.
Where the Time Actually Goes: The Pipeline Breakdown
The standard cascaded voice agent pipeline has six sequential stages, each contributing to the total latency. This is what Introl’s voice AI infrastructure guide published in January 2026 summarises as the core equation: STT + LLM + TTS + network + processing equals roughly 1,000ms for a typical deployment, even when individual components are performing well.
| Pipeline Stage | Typical Range | Optimised Target | Main Lever |
|---|---|---|---|
| Audio buffering + endpointing | 250 to 600ms | 20 to 80ms | Streaming chunks + smart endpointing model |
| Network upload (audio) | 20 to 100ms | 20 to 40ms | Edge proximity, WebSocket |
| STT processing (cloud) | 100 to 500ms | Sub-100ms (streaming) | Streaming Conformer model, regional endpoint |
| STT processing (on-device) | 250 to 520ms typical | Sub-50ms | CPU-first model, no network hop |
| LLM inference | 350ms to 1,000ms+ | 150 to 300ms | Model size, 4-bit quantisation, streaming |
| TTS synthesis (first audio) | 100 to 400ms | 40 to 95ms | Streaming TTS, fire on first sentence |
| Network download (audio) | 20 to 100ms | 20 to 40ms | Edge proximity, WebSocket |
| Total (unoptimised) | 800ms to 2,000ms | 300 to 500ms | Architecture across all layers |
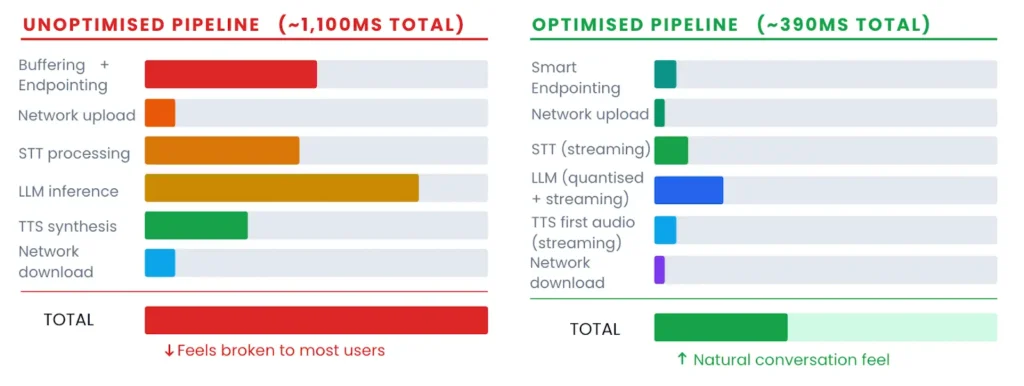
A few things stand out. First, audio buffering and endpointing are responsible for far more latency than most teams expect. Traditional silence-based endpointing defaults to a 500ms wait window before deciding a user has finished speaking. That 500ms alone exceeds the entire optimised target for some pipeline stages. Second, the LLM is almost always the single largest contributor once you have sorted the front end. Third, the gap between typical and optimised is not a technology gap. These optimised numbers are achievable today with components that are already in production.
Stage One: Audio Buffering and Endpointing
Most teams skip past this because it feels like plumbing rather than AI. That is a mistake. Endpointing is where many pipelines lose 300 to 600ms before any model has seen a single byte of audio.
Traditional end-of-turn detection works on silence. The system waits for the user to stop speaking, then waits a further 500ms silence window to confirm the turn is over, then passes the full buffer to STT. Most silence-based endpointing defaults sit around 500ms, and reducing that threshold is risky because natural pauses inside a sentence can look like end-of-turn events. The result is a system that either cuts people off mid-sentence or adds 500ms of avoidable latency on every turn.
Smart endpointing replaces silence detection with a trained model that reads richer signals: prosody, semantic completion, vocal pattern. Models must be built specifically for this task: detecting when a speaker stops talking as fast as possible. Because it should understand context rather than just silence, it can use tighter timing thresholds without the false-positive problem. Faster endpointing can directly reduce the time before the STT model even begins.
What to do at this stage
- Use 20ms streaming audio chunks rather than 250ms buffers. Smaller chunks mean transcription begins sooner.
- Replace silence-based endpointing with a dedicated smart endpointing model. The latency saving is 200 to 400ms per turn in most pipelines.
- Use WebSocket connections throughout. REST APIs add 50 to 100ms of connection overhead per request. Over a 10-turn conversation that is 500ms to 1 second of cumulative waste.
Stage Two: STT Processing and the Streaming vs Batch Divide
This is where most latency discussions start, but it is actually step two of the problem. STT architecture is the difference between a pipeline that can hit sub-100ms and one that cannot.
Batch STT waits for a complete audio buffer before transcription begins. Streaming STT transcribes continuously as audio arrives, returning partial outputs in real time using Connectionist Temporal Classification (CTC)-style alignment-free decoding approaches that produce frame-synchronous output without waiting for the full utterance. The difference in time-to-first-token is large: batch systems typically take 300 to 500ms, streaming systems deliver first tokens in under 100ms in production.
Conformer-based architectures have become the standard for low-latency streaming ASR. They combine convolutional layers for local acoustic patterns efficiently with self-attention for longer-range dependencies. A 2025 arXiv paper on telecom voice pipelines using a Conformer-CTC architecture achieved real-time factors below 0.2 on GPU, meaning the model processes audio faster than it arrives.
What to do at this stage
- Use a streaming model with a WebSocket interface, not a REST batch endpoint. The architecture choice alone shifts latency from 300 to 500ms to sub-100ms.
- For Indian enterprise deployments or any use case where audio cannot leave a defined network boundary, CPU-first on-device STT eliminates the network round-trip and often produces lower total latency than cloud despite processing entirely on commodity hardware.
- Match model to use case. If your deployment is Indic language, code-switched, or telephony audio, a model trained on those conditions will outperform a general-purpose model on both accuracy and effective latency, because fewer transcription errors means fewer correction cycles.
Stage Three: LLM Inference- The Biggest Budget Item
Once you have solved endpointing and STT, the LLM is almost always the place where latency budgets collapse. Standard LLM inference on a large model takes 350ms to well over one second depending on context length, model size, and available compute. For a pipeline already at 150ms STT, a 700ms LLM call produces a total latency of 850ms before TTS has even started.
AssemblyAI’s engineering team made a point worth quoting directly: reducing TTS latency from 150ms to 100ms sounds meaningful, but if your LLM takes 2,000ms, you have improved total latency by 2.5%. The optimisation effort should go where the time actually is.
There are four well-established approaches to this, all of them practical in 2026:
- Stream LLM output to TTS from the first token. Do not wait for a complete response before starting synthesis. Fire the TTS call as soon as the first sentence is available, then continue streaming. This parallelises two expensive stages and reduces perceived latency dramatically because the user begins hearing the response while the model is still generating.
- Apply 4-bit quantisation. A 2025 arXiv paper on telecom voice pipelines found that 4-bit quantisation achieves up to 40% latency reduction while preserving over 95% of original model performance. For most voice agent tasks, the accuracy tradeoff is imperceptible.
- Right-size the model. A 7B or 13B parameter model processes a turn significantly faster than a 70B model, and for most constrained voice agent tasks, intent classification, FAQ response, appointment booking, a well-prompted small model performs a large general model on both speed and cost.
- Pre-load retrieval context. If your agent uses RAG, load the domain documents before the call begins rather than retrieving at inference time. For constrained domains, cache common response patterns entirely to bypass inference for known queries.
What to do at this stage
- Implement streaming token-to-TTS from the first sentence. This single change typically reduces perceived latency by 200 to 400ms with no model changes.
- Profile your LLM’s P95 and P99 latency, not just averages. Spikes at P99 are what users complain about, and they often reveal queue depths, cold starts, or context length issues that averages mask.
- Test whether a smaller quantised model meets your quality bar before defaulting to the largest available model. For most voice agent use cases, it does.
Stage Four: TTS Synthesis and the Last Hundred Milliseconds
TTS has improved faster than any other component in the voice AI stack over the last 18 months. Most tools are genuinely fast, and the architecture for squeezing more out of TTS is straightforward: stream.
Start synthesis the moment the first sentence of LLM output arrives. Play that audio to the user while the model generates the second sentence. Continue streaming. The user experiences near-zero TTS latency because audio starts before synthesis is complete. Hamming AI’s latency guide notes that streaming TTS can reduce perceived latency to under 100ms for the user even when full synthesis takes 300ms, because what matters is time-to-first-byte, not time-to-complete-audio.
One nuance the Twilio team identified is worth keeping: a faster system can feel subjectively slower if the voice is less expressive. Prosody and naturalness affect perceived latency even when the actual milliseconds are the same. For customer-facing applications, test voice quality alongside speed metrics. A 10ms slower TTS that sounds noticeably more human often wins on user satisfaction even though it loses on the dashboard.
The Network Layer: The Variable Nobody Optimises
Model and pipeline choices get most of the engineering attention. Network architecture gets almost none of it, and for teams building in India, this is where the most avoidable latency lives.
Geography can create latency that no model optimisation can overcome. A round trip from Mumbai to a US-East endpoint adds 180 to 250ms of network latency purely from physics, before any processing. On a multi-turn conversation, that compounds to multiple seconds of cumulative overhead. The simplest fix is also the most impactful: use a regional endpoint.
| Architecture Choice | Latency Impact | When to Use |
|---|---|---|
| REST API (per request) | +50 to 100ms per turn | Batch workflows only, never for real-time voice |
| WebSocket (persistent) | Near-zero connection overhead | All real-time voice applications |
| Cloud, US endpoint (from India) | +180 to 250ms per turn | When data can leave India and regional is unavailable |
| Cloud, India regional endpoint | +20 to 50ms | Default for India deployments |
| On-device / on-premise | Sub-100ms (no network) | Regulated industries, air-gap, DPDPB compliance |
For Indian enterprise deployments, this is a critical calculation. The DPDPB and sector-specific regulations in BFSI and healthcare create data residency requirements that make US-endpoint cloud routing genuinely problematic, not just slow. On-premise or edge deployment of the STT layer solves both problems simultaneously; it eliminates the network latency penalty and satisfies data residency without any quality compromise, because modern CPU-first models run at production-grade accuracy without cloud infrastructure.
Putting It Together: A Realistic Latency Budget
Good latency engineering starts from a budget. Here is a realistic target breakdown for a sub-500ms voice agent pipeline using current technology:
| Component | Target Budget | How to Hit It |
|---|---|---|
| Audio buffering | 20 to 40ms | 20ms streaming chunks, WebSocket from the start |
| Smart endpointing | 50 to 80ms | Dedicated endpointing model, not silence detection |
| STT (cloud, regional) | 80 to 120ms | Streaming Conformer CTC, India regional endpoint |
| STT (on-device) | Sub-50ms | CPU-first model, zero network overhead |
| LLM inference | 150 to 250ms | 7B to 13B quantised model, stream from first token |
| TTS first audio | 40 to 95ms | Streaming TTS, fire on first LLM sentence |
| Network round-trip | 20 to 40ms | Regional endpoint or on-device, WebSocket |
| Total (cloud path) | 360 to 525ms | Well-architected cascaded pipeline |
| Total (on-device STT) | 280 to 415ms | On-device STT + cloud LLM + streaming TTS |
A few things stand out in this budget. The LLM is still the single largest item, which is why right-sizing it matters more than shaving milliseconds off TTS. On-device STT produces lower total latency than cloud STT in most India deployments, because eliminating zooms of network overhead outweighs any processing difference. The gap between the optimised total and the typical production total, 300 to 500ms versus 800 to 2,000ms, is not explained by model capability. It is explained by architecture decisions at every stage.
The teams winning on latency are not using faster models. They are using better architecture; streaming at every layer, right-sized LLMs, regional or on-device inference, and WebSocket connections throughout.
Latency Is an Architecture Problem
The teams shipping sub-500ms voice agents in 2026 are not using secret models or experimental infrastructure. They are making better architecture decisions at every layer: streaming audio from the start, using smart endpointing instead of silence windows, right-sizing their LLMs, streaming TTS from the first token, and placing inference as close to users as data residency requirements allow.
Sub-100ms STT is achievable today. The gap between that and a total pipeline below 500ms is a series of well-understood engineering choices, not unsolved problems. The reason most production agents are still at 800ms to two seconds is that teams optimise components in isolation rather than profiling the pipeline as a whole and finding the actual bottleneck.
For teams building in India, for BFSI, healthcare, contact centres, regional language applications, there is an additional dimension. Geography is a physics problem, not a software problem. On-device CPU-first STT resolves it cleanly: no network round-trip, full data residency compliance, and latency performance that often beats cloud from a standing start. The architecture that satisfies compliance requirements turns out to also produce the fastest pipelines.
Build the pipeline right from the start. Latency is much easier to architect in than to retrofit.
Try Zero STT by Shunya Labs
Zero STT is built for low-latency production deployment: CPU-first architecture, streaming Conformer-CTC models, sub-100ms on-device and full on-premise or edge deployment for Indian data residency requirements.
Covers 200+ languages including all major Indic languages. Production-grade accuracy on telephony audio, code-switched speech, and noisy environments.
View latency benchmarks at shunyalabs.ai/benchmarks or start with free API credits at shunyalabs.ai/zero-stt.
References
- Assemblyai.com. (2025). The 300ms rule: Why latency makes or breaks voice AI applications. [online] Available at: https://www.assemblyai.com/blog/low-latency-voice-ai [Accessed 11 Mar. 2026].
- Digital Minds BPO (2024). 30+ Eye-Opening Call Center Statistics and Metrics You Must Know in 2025. [online] Outsourcing Philippines | Digital Minds BPO. Available at: https://digitalmindsbpo.com/blog/call-center-statistics.
- Ethiraj, V., David, A., Menon, S. and Vijay, D. (2025). Toward Low-Latency End-to-End Voice Agents for Telecommunications Using Streaming ASR, Quantized LLMs, and Real-Time TTS. [online] arXiv.org. Available at: https://arxiv.org/abs/2508.04721 [Accessed 11 Mar. 2026].
- Introl.com (2026). Welcome To Zscaler Directory Authentication. [online] Available at: https://introl.com/blog/voice-ai-infrastructure-real-time-speech-agents-asr-tts-guide-2025 [Accessed 11 Mar. 2026].
- Xu, M. (2026). Voice AI Latency Benchmarks: What Agencies Need to Know in 2026. [online] Trillet.ai. Available at: https://www.trillet.ai/blogs/voice-ai-latency-benchmarks [Accessed 11 Mar. 2026].
- You.com (2026). You.com | What Is P99 Latency? Why It Matters and How to Improve It. [online] Available at: https://you.com/resources/what-is-p99-latency [Accessed 11 Mar. 2026].