Most people first encounter Voice AI through a voice assistant. You say something. It responds. Simple enough. But what happens in the middle is a lot more sophisticated than it looks.
Voice AI refers to any AI system that can process, interpret, or generate human speech. That includes systems that listen and understand spoken input (speech to text), systems that speak back from written content (text to speech), and systems that manage the full conversation loop from input to response to output.
The reason Voice AI feels so different today compared to three or four years ago comes down to one thing: neural models. Older voice systems were rule-based. They matched patterns. Modern systems have learned from millions of hours of real human speech and understand things like context, tone, rhythm and intent.
The best Voice AI does not just process language. It understands the weight behind it. When someone says “I need help,” it knows that is not the same as “I have a question.”
8.4B
Voice assistants active worldwide
$50B+
Projected Voice AI market by 2030
71%
Mobile users prefer voice over typing
These numbers point to something real. Voice is becoming the default interface for a growing number of digital interactions. The products that get this right will feel native to how people actually communicate. The ones that get it wrong will feel like a chore.
What Text to Speech/ Type to Speech really means in 2026
Text to Speech has been around for decades. But the version that existed even five years ago is barely recognisable compared to what is possible today.
At its core, Text to Speech (TTS) is the process of converting written text into spoken audio. Feed in a sentence. Get back a voice. That part has not changed. What has changed is everything about the quality, expressiveness, and speed of that conversion.
Modern TTS systems do not just read. They perform. They know that a question ends differently from a statement. They can adjust pacing, warmth, and weight based on what the content actually needs.
The practical value is bigger than most people realise
Content teams are using TTS to produce audio versions of every article they publish, without booking a studio. E-learning platforms are building full courses in 30 languages without a voiceover artist. Healthcare providers are delivering post-appointment instructions in a patient’s own language at the click of a button.
These are not edge cases. They are the normal applications of a technology that has matured to the point where quality is no longer a barrier.
At Shunya Labs, the focus has been on naturalness at scale. Not just one good voice, but a system that sounds right across accents, languages and content types. When you read a sentence back to yourself and it sounds like someone said it rather than something read it, that is the bar we are holding ourselves to.
These technologies are strongest when they work together
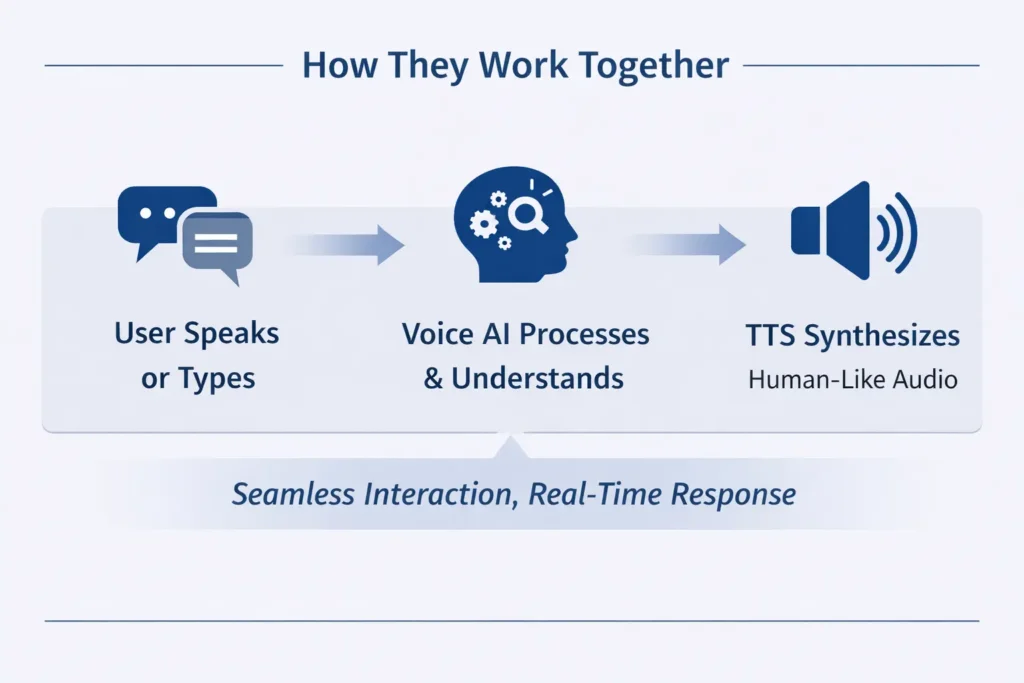
Voice AI, Text to Speech or Type to Speech are not competing. They are complementary. Each addresses a different point in the communication chain.
Voice AI handles understanding and generating language. Text to Speech handles the conversion of that language into natural audio and handles the real-time delivery of that audio during live interactions.
A well-built voice application uses all. A user speaks or types a question. The Voice AI interprets it and generates a response. The TTS engine renders that response in a voice that sounds human. If the interaction is live, the Type to Speech layer ensures there is no uncomfortable gap between response and delivery.
Getting this stack right is harder than it looks. Each layer needs to perform well independently and hand off cleanly to the next. A great TTS model plugged into a slow Voice AI pipeline can still produce a bad experience. The quality of the whole system depends on the quality of every part.
This is where Shunya Labs puts its energy. We are not building one piece and calling it done. We are building the full stack with the same level of care at every layer. Our speech to text model handles accurate transcription across accents and noise conditions. Our TTS model is designed to match that same standard for naturalness and reliability. And the architecture underneath both is built for real-time performance.
What strong voice AI looks like in practice
It is easy to talk about voice quality in abstract terms. Here is what it actually looks like when a voice AI platform is doing its job properly.
A call centre agent powered by voice AI picks up on the frustration in a customer’s voice and routes them to a human before they have to ask. A language learning app speaks back a student’s sentence with natural rhythm, not just correct phonemes. A content platform reads an article in a voice that matches the publication’s tone, not a generic neutral default.
These outcomes require more than a decent model. They require latency that does not make interactions feel laggy. They require multilingual support that actually works across dialects, not just primary languages. They require the ability to fine-tune or customise voice output to fit a brand or context.
Shunya Labs is built with these outcomes in mind. Not as feature checkboxes but as the standard we design around.
Where voice technology is heading and what it means for you
The near-term direction is clear. Models are getting faster. Personalisation is getting deeper.
A few things worth watching over the next 12 to 18 months:
Emotion-aware synthesis. TTS systems that adjust tone and pacing based on the emotional weight of the content, not just the words.
Multilingual voice at production quality. Not translation-quality audio but broadcast-quality output across 50 or more languages from a single input.
Custom brand voices. Businesses create unique AI voices that are consistent across every customer touchpoint, from support calls to product narration.
Ambient voice interfaces. As more devices become voice-first, the interaction layer shifts from screen to speech for a growing share of daily tasks.
Fully integrated voice agents. AI systems that listen, reason, and respond in speech in real time, with the full context of a conversation maintained throughout.
Each of these directions places more weight on the quality of the underlying voice models. The teams and platforms investing in that quality now will be the ones positioned to build on it when these use cases become standard.
At Shunya Labs, that investment is already underway. With our capabilities of building custom full stack models, we are building toward a platform that handles the full voice layer for the products and teams that need it.
Final thought
Voice AI, Text to Speech and Type to Speech are names for specific tools. But they are all working toward the same thing. Communication that does not feel like a workaround.
The gap between how humans talk to each other and how they talk to technology has been closing for years. In 2026, that gap is smaller than it has ever been. The tools are good enough now that the focus can shift from “does this work” to “does this feel right.”
That is the question driving the work at Shunya Labs. And it is a question we think the industry is finally ready to answer well.
Dutoit, T. (2011). High-Quality Text-to-Speech Synthesis: An Overview.[online] Journal of Electrical and Electronics. Available at:https://www.academia.edu/416816
Most speech AI platform evaluations start in the wrong place.
Teams look at marketing demos. They check whether a platform transcribes clean English well. They compare pricing tiers. Then they pick something and build on it. A few months later they discover it does not work on their actual audio, in their actual languages, under their actual compliance requirements.
The problem is not that those teams made bad decisions. It is that they evaluated the wrong things.
A speech AI platform that works brilliantly for a US-based SaaS company can fail completely for an Indian BFSI enterprise. Not because the platform is bad. Because the fit was wrong from the start.
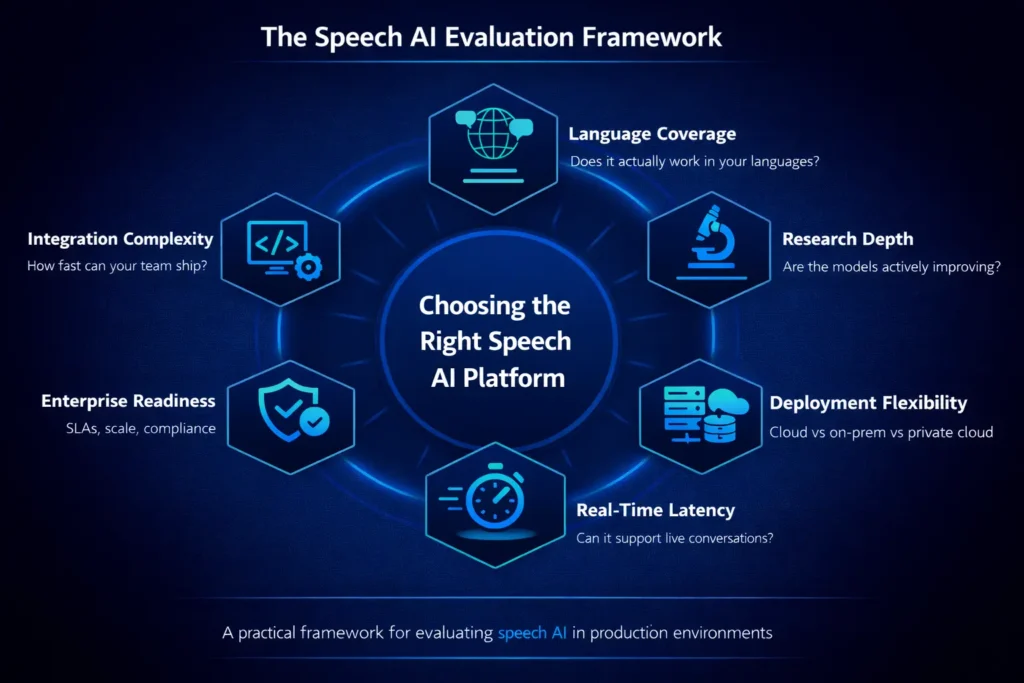
This guide covers the six criteria that actually determine whether a speech AI platform works in production. Each one has a concrete test you can run before you commit to anything.
Criterion 1: Language Coverage That Matches Your Users
Language support is one of the most misrepresented metrics in speech AI. A platform that claims to support 50 languages is not the same as a platform that works well on 50 languages.
The difference lies in how each language was trained. Global platforms add languages by extending their English-first models. That works for languages with large clean audio datasets: German, French, Mandarin, Spanish.
It does not work when training data is thin, dialect variation is high, or real deployment audio looks nothing like studio recordings. That describes most Indian languages.
For India, this gap is especially wide. The country has 22 official languages and hundreds of dialects. Code-switching between languages mid-sentence is standard for millions of speakers. A model trained primarily on English and extended to Hindi does not handle Bhojpuri, Marathi, or Telugu telephony speech reliably.
So the question to ask is not how many languages a platform supports. It is: which languages were trained on real-world audio in real deployment conditions, and what is the word error rate on those languages measured independently?
What to test
Request WER data specifically for your target languages on telephony-quality audio, not studio recordings.
Ask whether the model was trained on code-switched speech if your users mix languages mid-sentence.
Run a blind test: record a few minutes of audio from your actual callers and test every shortlisted platform on the same file.
Platforms trained on real-world audio for a language will perform significantly better than those that have extended English-first models.
Shunya Labs models cover 200 languages including 55 Indic languages. Each Indic language is trained on real audio, code-switched speech, and regional dialect variation, not extended from an English base.
Criterion 2: Research Depth Behind the Models
Every speech AI platform has models. Not every platform has a research programme that is actively improving those models based on how they actually fail in production.
The distinction matters more than it might seem. Speech AI is not a solved problem. Real-world audio is noisy, compressed, and full of domain-specific vocabulary that general models have never seen. A platform built on top of commodity models from three years ago will hit accuracy ceilings that a research-led platform can push past.
Research-led platforms publish papers, benchmark against independent datasets, and improve their architectures continuously. You can see it in their model versioning history and their domain-specific vocabulary performance. Are they shipping new architectural approaches, or just repackaging existing ones?
The practical test is simple: ask the vendor what changed between their last two model versions and what specific problem each change solved. A vendor with a real research programme can answer that precisely. A vendor reselling a commodity model usually cannot.
What to look for
Published research papers and benchmarks, especially on non-English and low-resource languages. Model architecture that reflects recent advances, not just fine-tuned versions of 2022-era models. A clear roadmap for specific language improvements, not generic promises of ‘continuous improvement’. Benchmark results on independent third-party datasets, not just internal evaluations.
Zero STT by Shunya Labs is the most accurate speech recognition model on OpenASR benchmarks, achieving 3.10% World Error Rate (WER). The Indic language models were not adapted from English. They were built from the ground up on Indic audio data, which is why we achieve 3.1% WER on Indian speech where global platforms struggle.
Criterion 3: Deployment Flexibility for Regulated Industries
This is the criterion that eliminates the most platforms fastest, especially for Indian enterprise.
Regulated industries like BFSI and healthcare cannot route audio to infrastructure they do not control. Under PDPB guidelines and RBI circulars, audio from Indian customer calls generally cannot leave India. Under HIPAA-equivalent frameworks in healthcare, patient audio must stay within defined boundaries.
Most global speech AI platforms are cloud-only. You send audio to their US or EU servers, you get a transcript back. That architecture is simply not compliant for Indian BFSI or healthcare regardless of how good the transcription quality is.
The platforms that work in regulated contexts offer one of three things. On-premise deployment, where the model runs on your own hardware. India-hosted infrastructure, where audio stays within Indian data centres. Or private cloud within a defined boundary you control.
Ask your vendor three specific questions. Is the on-premise model the same version as the cloud model? Does it support streaming ASR? Can it run on CPU hardware without GPU infrastructure?
What to ask your vendor
Is on-premise deployment available, and is it the same model as the cloud version? Does it support streaming ASR in on-premise mode? Can it run on CPU-only hardware, or does it require GPU servers? What is the minimum hardware specification for a production deployment at your expected concurrent load? Is India-hosted cloud infrastructure available as an alternative to on-premise?
Zero STT runs fully on-premise on CPU hardware, with no GPU requirement. This is the architecture that makes it viable for BFSI and healthcare teams in India who cannot route audio outside their own infrastructure.
Criterion 4: Real-Time Latency That Supports Live Conversation
If you are building anything interactive, latency is not a performance metric. It is a product requirement.
Human conversation has a natural response window of 200 to 300 milliseconds. When a voice agent exceeds that, the interaction can start to feel broken. Users talk over the agent. Trust drops. Task completion falls.
There are two latency numbers to care about. The first is streaming STT time-to-first-token: how quickly the ASR layer returns text after audio starts arriving. This should ideally be under 500 milliseconds for production real-time applications. The second is end-to-end turn latency: from the user stopping speaking to the agent starting its response. This should be under 800 milliseconds for natural conversation.
Most vendor latency claims are measured in ideal conditions: clean audio, fast networks, small models. Real Indian deployments add variables that inflate those numbers. Telephony audio compression. India-to-US network round-trips can add 180 to 250 milliseconds per turn. On-device inference removes the network round-trip entirely, which is why it consistently beats cloud-routed alternatives for Indian field operations and contact centre use cases.
What to measure
Streaming STT time-to-first-token: should be under 500ms. Test on your actual audio format, not a clean demo file. End-to-end turn latency: should be under 800ms for live conversation. Measure from end of speech to start of agent audio. Measure at your expected peak concurrent load, not on a single test call. For India deployments: measure latency with India-origin audio.
Criterion 5: Enterprise Readiness Beyond the Demo
There is a significant gap between a platform that works in a proof-of-concept and one that works at production scale in an enterprise environment.
Enterprise readiness covers several things that often do not show up in a demo. Concurrent connection limits: how many simultaneous calls can the platform handle before quality degrades? SLA terms: what uptime is guaranteed, and what compensation exists if it is not met? Support response times: when something breaks at 2am before a launch, who answers?
For Indian enterprise specifically, there are additional dimensions. Does the vendor have experience with Indian audio at scale? Can they provide Indian reference customers in your vertical? Do they understand the specific compliance requirements of RBI, IRDAI, or the healthcare data frameworks you operate under?
A vendor who has only shipped to US enterprises will know the HIPAA and SOC 2 landscape well. They will not necessarily know how Indian BFSI compliance maps to deployment architecture, or what audit documentation Indian regulators expect. That knowledge gap creates risk.
Enterprise checklist
Concurrent call capacity at your expected peak load, with documented degradation behaviour above that limit. SLA with uptime guarantees and clear remediation terms, not just ‘best effort’. Support tier that includes named contacts and response time commitments for production issues. Reference customers in your vertical and geography, not just logo references. Compliance documentation relevant to your regulatory framework, not just generic SOC 2 or GDPR certification.
Criterion 6: Integration Complexity and Time-to-Production
A platform that takes three months to integrate is not a good platform for teams with a six-month roadmap.
The integration complexity question covers two things. First, the API design: is it REST or WebSocket? For streaming ASR, WebSocket is standard and integrates in hours. Complex authentication schemes like AWS Signature V4 or proprietary gRPC can add weeks to integration timelines, especially for teams without deep cloud experience.
Second, SDK quality. A well-maintained SDK with working examples cuts integration time from weeks to days. Ask to see it before you commit. Run the quickstart. If it takes over an hour to get a working transcription from a test file, that can tell you something about the full integration experience.
For voice agent applications, also ask about the full pipeline. Does the platform provide just ASR, or does it offer a complete STT-plus-LLM-plus-TTS pipeline? If you need to wire three separate vendors together, you own the integration surface and every latency problem at each handoff. Some teams prefer that control. For others, a unified pipeline is worth the reduced flexibility.
Integration signals to watch
WebSocket API for streaming ASR: integrates in hours. Complex auth schemes: add days to weeks. Working SDK quickstart that runs in under an hour. Active documentation with examples in your language stack. Clear answer on whether pipeline components (STT, LLM, TTS) can be used independently or only as a bundle.
Criterion 6: Integration Complexity and Time-to-Production
How Leading Platforms Compare on These Six Criteria
This table uses publicly available information and is accurate as of March 2026. Enterprise features and pricing change frequently. Verify with vendors before making a final decision.
Platform
Indic Language Support
Research-Led Models
On-Premise / CPU
Streaming Latency
India Enterprise Focus
Integration Ease
Shunya Labs
200 languages, 55 Indic (deep)
Yes
Yes, CPU-only
Excellent, Sub-50ms on-device
Yes
Excellent WebSocket
Deepgram
Limited (English-first)
Yes, active research
Yes (GPU required)
Excellent
No
Excellent
Azure Speech
Hindi, some Indic
Large scale, broad
Yes (GPU required)
Good
Partial
Good
Google STT
22 languages (limited depth)
Broad, English-first
Via Anthos (complex)
Good
No
Good
AssemblyAI
Very limited
Yes, active research
Yes (self-hosted)
Good
No
Good
Speechmatics
Limited
Yes, strong research
Yes
Excellent
No
Good
Frequently Asked Questions
What is the most accurate speech AI platform for Indian languages?
Accuracy on Indian languages depends entirely on which languages you need and what audio conditions you are working with. For standard Hindi in clean audio, most major platforms perform acceptably. For regional Indian languages like Telugu, Marathi, Bhojpuri, Odia, or Assamese over telephony audio, platforms specifically trained on Indic data perform significantly better. The only reliable way to measure this is to test on your actual audio, not rely on vendor-provided benchmarks. Shunya Labs is one of the platforms that has high accuracy in Indic languages.
Can a speech AI platform run without sending audio to the cloud?
Yes, several platforms offer on-premise deployment. The important check is whether the on-premise version uses the same model as the cloud version and whether it supports streaming ASR. Some vendors offer on-premise as a reduced-feature option, which is worth clarifying before you build your architecture around it. CPU-first on-premise deployment, which runs without GPU hardware, is the most practical option for most Indian enterprise teams.
How many languages does a speech AI platform need to support?
The number matters less than which languages and how well. A platform that supports 10 languages with production-grade accuracy on real-world audio is more useful than one that supports 100 languages at inconsistent quality. For India, a practical enterprise deployment often needs 5 to 10 specific Indic languages at high accuracy, plus Indian-accented English. Start with your actual user distribution and work backwards to the language requirement.
What should I prioritise when choosing between a specialised platform and a big cloud provider?
Big cloud providers win on ecosystem integration, geographic coverage, and compliance certifications for Western regulatory frameworks. Specialised platforms win on accuracy for specific domains or languages, deployment flexibility, and typically on latency. For Indian enterprise teams who need Indic language accuracy, on-premise deployment, and a vendor who understands Indian compliance requirements, a purpose-built platform is almost always the better choice. The integration and ecosystem tradeoffs are real, but they are usually solvable. The language accuracy gap is much harder to close after deployment.
The Evaluation Framework in Summary
Run through these six questions before you shortlist any speech AI platform:
Does it support your specific languages at production-grade accuracy on real-world audio, not just in demos?
Is there genuine research behind the models, or is it a fine-tuned commodity model with a marketing layer?
Can it run on-premise on CPU hardware, with the same model and streaming support as the cloud version?
What is the measured end-to-end latency on your actual audio format at your expected call volume?
Does the vendor have enterprise-grade SLAs, support, and reference customers in your vertical and geography?
How long does integration actually take? Run the quickstart before you commit.
The platforms that clear all six bars are a short list. That is the point. Better to know that before you build than six months into a production deployment.
200 languages including 55 Indic languages, trained on real audio and code-switched speech. Not extended from English. Most accurate speech recognition model with 3.1% WER. On-premise, CPU-first deployment. Same model as cloud. Full streaming ASR support. PDPB and RBI-compliant architecture. Enterprise deployments in BFSI and healthcare. Start free at shunyalabs.ai or talk to the team at shunyalabs.ai/contact
Speech AI is not one technology. It is a stack: STT converts speech to text, LLMs reason over it, TTS turns a response back into speech. Each layer has improved dramatically since 2023.
Real-time voice went from demo-quality to production-ready in 2025 when latency dropped below 500ms consistently. That single threshold change opened the market.
India’s voice AI opportunity is unlike anywhere else: 22 official languages, 1.2 billion mobile users, and industries like BFSI and healthcare with massive call volumes and severe automation gaps.
The five industries being transformed fastest are BFSI, healthcare, contact centres, field operations, and media. Each has its own dynamics and readiness level.
Platform matters more than model. Teams that pick the right foundational speech infrastructure avoid rebuilding from scratch as requirements evolve.
Speech AI gets thrown around as though it means one thing. It does not. When a call centre deploys a voice bot, that is speech AI. When a doctor dictates clinical notes and they appear as text without typing, that is also speech AI. When a video gets dubbed into six regional languages overnight, same category.
These applications feel very different because they solve different problems. But they all use the same three technologies: something that listens, something that reasons, and something that speaks. Understanding each layer helps you choose the right tools. It also helps you have better conversations with vendors who will often blur the lines.
This post explains what speech AI is. It covers how each layer works, where it breaks down, and what real-world use looks like today.
What Speech AI Actually Is in 2026
The term is used to mean at least four different things. Knowing the difference matters when you are picking infrastructure.
The first and most basic is speech recognition, or ASR. It converts spoken audio into text. This is what people mean by STT (speech to text). It is the input layer of any voice application. Everything downstream depends on how accurate and fast this step is.
The second is speech synthesis, or TTS. It converts text back into spoken audio. In 2026, neural TTS often sounds just like a human in controlled conditions. The AI voice generator market was worth $4.16 billion in 2025. It is projected to reach $20.71 billion by 2031, growing at 30.7% CAGR (MarketsandMarkets). The TTS segment is led by APIs and developer tools, growing fastest at 34.7% CAGR.
The third is voice AI agents. These systems combine STT, an LLM, and TTS into a real-time conversation loop. They power the voice bots handling customer calls, taking appointments, and processing loan applications. This segment is the fastest-growing part of the stack. It was estimated at $2.4 billion in 2024 and is projected to reach $47.5 billion by 2034.
The fourth is speech analytics. It processes recorded or live calls to pull out useful data. This includes sentiment, compliance flags, key phrases, emotion detection, and agent quality scores. It serves a different buyer than the real-time stack. But it runs on the same underlying speech recognition models.
Each layer has different performance needs and different vendors. You would not choose a TTS provider based on STT benchmarks. You would not evaluate an analytics platform the same way you evaluate a live agent system. Knowing which layer you need is the first decision you have to make.
The Three Layers That Make Up Speech AI
Every speech AI system is built from some mix of three parts. You can use each one on its own. But the most powerful apps combine all three.
Layer 1: Speech Recognition (ASR / STT)
This is the listening layer. Automatic Speech Recognition (ASR) converts spoken audio into text. It is the input to everything else. If this step is inaccurate, nothing else works well.
Modern ASR models use deep learning. Most are built on Conformer or Transformer architectures, trained on thousands of hours of audio. They learn patterns: which sounds map to which words, in which contexts. When a model is trained on one language and used on another, those patterns break. A model with 5% error on US English can easily hit 25% or higher on regional Indian languages over phone audio.
In 2026, the key technical split is between batch and streaming ASR. Batch ASR waits for a full recording before transcribing. Streaming ASR processes audio as it arrives and returns text in real time. For analytics, batch works fine. For any live voice interaction, streaming is not optional. The architecture sets the latency floor for the whole app.
Layer 2: Language Models (LLM)
Once you have text, something needs to understand it and decide what to do. In most modern speech AI systems, that is a large language model (LLM). The LLM reads the transcript, reasons over it, and either responds or takes an action.
The LLM is where most of the intelligence lives. It decides whether the agent handles tricky questions, topic switches, or domain-specific queries. It also decides when to hand off to a human. The ASR layer gives the LLM words. The LLM decides what those words mean and what to do about them.
For real-time voice, LLM response time is usually the biggest cause of delay. A well-configured STT layer might add 100ms. A standard LLM call on a large model adds 400ms to over 1 second. This is why model size matters. A well-prompted 7B parameter model handles most voice agent tasks faster and cheaper than a 70B model. For constrained tasks like booking or collections, there is no meaningful quality difference.
Layer 3: Speech Synthesis (TTS)
The output layer converts the LLM’s text response back into spoken audio. TTS has improved faster than any other part of this stack over the last two years. Neural TTS voices today are often hard to tell from human recordings in controlled conditions.
Most people miss one thing about TTS in real deployments: voice quality affects how smart the agent seems. A slow, robotic response feels less trustworthy, even if the words are the same. For customer-facing apps in India, callers are sensitive to whether the agent sounds like it understands them. TTS quality directly affects task completion rates.
Speech AI in Practice: The Five Industries Being Transformed Fastest
1. BFSI The Highest Volume, the Highest Stakes
Indian banks and insurers handle tens of millions of customer calls every month. Most of those calls cover a small set of needs: balance queries, EMI schedules, policy renewals, claim status, and loan eligibility.
In FY23-24, 95 Indian banks received over 10 million complaints. The RBI is pushing banks to use AI to sort, tag, and resolve them faster. 57% of BFSI institutions already use voice analytics to track interaction patterns, according to Mihup.ai (October 2025).
Key use cases span five workflows: customer onboarding, loan processing and collections, fraud detection via voice biometrics, policy renewals, and multilingual support. HDFC and ICICI are publicly deploying voice bots for onboarding and queries. NBFCs are using AI calls for lead qualification and collections. One analysis found lead qualification costs falling from Rs 800 to Rs 120 per lead with voice AI. Organisations report 20–30% cuts in operating costs overall.
Compliance adds a layer specific to India. PDPB rules mean audio from Indian customer calls cannot freely leave the country. For BFSI, voice AI that runs on-premise or on India-hosted endpoints is not a nice-to-have. It is the only viable architecture.
2. Healthcare: The Fastest Growing Adoption Rate
Healthcare conversational AI is growing at 37.79% CAGR, the fastest of any sector. Voice AI could save the US healthcare economy $150 billion annually by 2026, according to Fortune Business Insights. But the India story is different. Here, the priority is not saving physician time on paperwork. It is reaching patients who had no access before
A Hindi-speaking patient in a tier-3 city needs a system that speaks their language. It must understand medical terms in that language and handle regional accents. Global ASR models often fail at this. Models trained on clean English clinical speech do not transfer to code-switched, accented Hindi medical calls.
The problem in Indian healthcare is not lack of willingness to adopt. It is the quality of speech models on Indic languages in clinical settings.
3. Contact Centres and BPO: The Structural Disruption
India’s BPO industry is facing its sharpest challenge in two decades. Traditional call centres run 30-50% attrition, night-shift fatigue, and rising costs. One voice AI agent can handle thousands of calls a day with none of those constraints. The ROI numbers are stark: e-commerce support costs drop 40-50%, productivity gains reach 320%, BFSI query resolution improves up to 80%, and customer satisfaction scores rise 12+ points.
The pattern emerging is not full replacement. It is tiered automation. Tier 1 queries go to voice AI. Tier 2 queries use AI with human escalation. Tier 3 goes to human agents with AI assist. Smaller Tier-2 BPOs are already winning hybrid deals. The phrase in enterprise RFPs today is simply: Are you AI-ready?
India’s call centre industry is projected to grow at 8-10% CAGR over the next five years. Voice AI is not stopping that growth. It is reshaping what that growth looks like.
4. Field Operations: The Overlooked Vertical
The least talked-about but most India-specific use of voice AI is in field operations. This covers insurance agents, FMCG field sales, microfinance collection agents, agricultural workers, and logistics staff. These workers are mobile, often in low-connectivity areas, frequently non-English speaking, and work entirely through conversation.
As Mathangi Sri Ramachandran of YuVerse noted in Inc42’s January 2026 analysis, voice is going to occupy a lot of the commercial transaction space in India. Voice can be used to troubleshoot machines on-site. Field agents use it to log activity, process collections, and update CRMs without typing. For these users, voice is not a convenience. It is the only interface that fits how they work.
On-device speech models The infrastructure here has distinct needs. It requires offline capability or very low connectivity tolerance. It needs sub-100ms STT on CPU hardware without cloud round-trips. It also needs strong support for regional languages at high noise levels. This is exactly where on-device speech models outperform cloud-based options on every metric that matters.
5. Media and Entertainment: The Scale Play
The media vertical is growing in a different way. The driver is not automating human conversations. It is creating new content at a scale that was not possible before. Key use cases include multilingual dubbing, regional voiceovers for OTT content, AI audio narration for short video, and dynamic ad personalisation by language and dialect.
The media and entertainment segment holds the largest revenue share in AI voice generators. For India, the value is localisation at scale. Dubbing a series into 10 regional languages manually takes months and costs crores. AI-assisted dubbing with voice cloning can cut both to days and lakhs.
Industry
Adoption Stage
Primary Use Cases
Key India Factor
BFSI
Scaling fast
Collections, onboarding, fraud detection, multilingual support
PDPB compliance requires on-premise or India-hosted infra
Regional language accuracy in clinical contexts is unsolved globally
Contact Centres
Structural disruption
L1 automation, quality monitoring, agent assist
30-50% attrition makes AI augmentation essential, not optional
Field Operations
Early but strategic
Activity logging, collections, CRM update via voice
Offline capability and low connectivity tolerance required
Media / OTT
Volume play
Dubbing, voiceover, regional audio content at scale
22 official languages creates localisation demand no other market matches
How to Think About Choosing a Speech AI Platform
The Google keywords data shows that searches for ‘voice AI platform’ are growing 9,900% YoY and ‘conversational AI platform’ are growing 900% YoY. These searches may come from buyers who have decided they need something and are now comparing options. How you frame the decision matters.
Real-time voice agents need sub-500ms end-to-end latency. Analytics platforms instead require vocabulary accuracy and cross-language prosody support.
Start with deployment requirements, not features
The most common mistake when evaluating speech AI is starting with model accuracy benchmarks on English audio. For most Indian enterprise deployments, the first filter should be deployment mode. Can this run on-premise? Can audio stay within Indian infrastructure? Is there a CPU-first option with no GPU needed? These questions alone rule out most global cloud providers before you even compare features.
Measure what matters for your use case
Real-time voice agents need sub-500ms end-to-end latency and sub-100ms STT time-to-first-token. Analytics platforms need high keyword recall and domain vocabulary accuracy. Dubbing workflows need natural voice quality and cross-language prosody. These are different metrics. Picking a provider based on one universal benchmark can miss this entirely.
Test on your actual audio
Published WER benchmarks use standard clean audio. Production Indian audio is not a clean corpus. The only number that matters is the error rate on your actual audio: your callers, your languages, your conditions, your domain vocabulary. Any speech AI provider worth evaluating will let you run that test before you commit.
Think about the full stack before picking a layer
If you are building a voice agent, you need STT, an LLM, and TTS. If you pick these from three separate providers, you own the integration, the latency budget, and the failure points. Some teams prefer that control. Others prefer a platform that handles the full pipeline. The right answer depends on your engineering capacity and how much of the stack is core to your product.
How Shunya Labs Fits Into This
Shunya Labs is built specifically for the deployment constraints that matter most in Indian enterprise: CPU-first architecture that runs on-premise without GPU hardware, sub-100ms on-device latency, and models trained on Indic audio with production-grade accuracy. 200-plus language support including all major Indic languages and dialects. n. For BFSI, healthcare, and field operations teams who cannot route audio to cloud infrastructure or need latency that cloud round-trips make impossible, on-device speech AI is not a tradeoff. It is the right architecture.
K Vijayvasuganthi, Ravichandran G., and PARAMASIVAN C (2025). The Impact Of AI-Powered Chatbots On Customer Satisfaction In E-Commerce – A Study With Special Reference To Chennai City. [online] Available at: https://www.researchgate.net/publication/396388313.