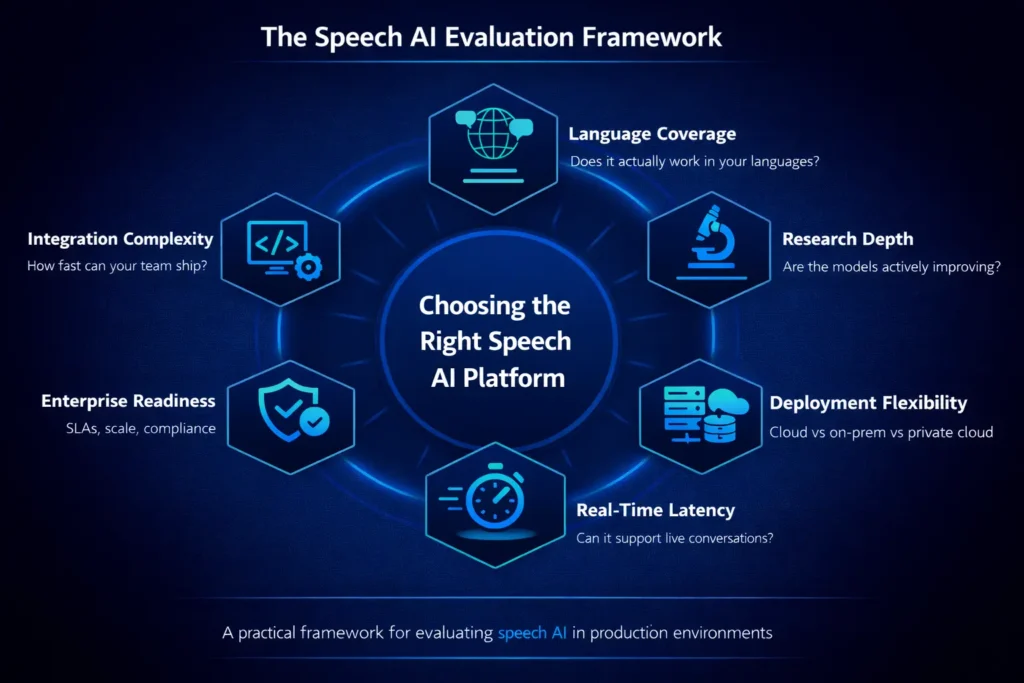
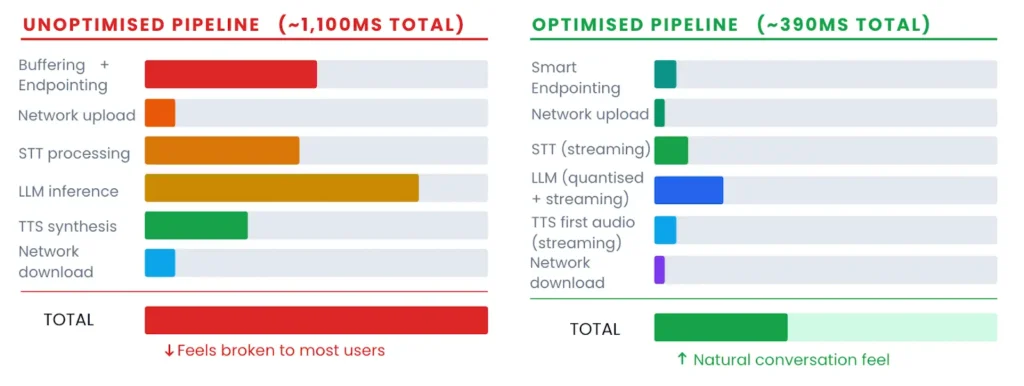
The voice AI market is moving fast. Most platforms promise the world in a demo and quietly fall short the moment real users start talking. Here is what actually separates a production-ready speech AI platform from everything else.
The numbers tell a clear story. The global voice recognition market was valued at $18.39 billion in 2025 and is on track to hit $61.71 billion by 2031, growing at a compound annual rate of 22.38% (Mordor Intelligence). Enterprise adoption is leading the charge. Large organisations account for more than 70% of voice AI market spending today.
Yet for all that growth, a fundamental problem persists. Most speech AI platforms were built with English at the centre and everything else bolted on later. That works for a narrow set of use cases. It fails the moment you need to serve customers in Tamil, Marathi, or Swahili at any real scale. Learn why standard models fail on mixed languages.
This post is for the product and technology leaders asking the right question: not just “which speech AI platform is best” but “which platform was actually built for what we need?” At Shunyalabs, we think that question has a straightforward answer, and we want to lay out the reasoning behind it.
The Language Problem Nobody Is Solving Well
India reached 886 million active internet users in 2024, growing at 8% year on year. Nearly all of them, 98%, access content in Indic languages. Even in urban areas, 57% of internet users prefer consuming content in their regional language over English (IAMAI and KANTAR Internet in India Report 2024).
Those numbers represent a massive, largely underserved user base. And they are growing faster than any other segment. Rural India now accounts for 55% of the country’s total internet population and continues to grow at double the rate of urban regions. These users are not switching to English. They are demanding better services in the languages they have always spoken.
For a business deploying a voice bot, an IVR system, a transcription service, or an ai speech product, this is not a niche consideration. It is the core product requirement. And it is where most speech AI platforms run out of answers.
THE REAL GAP IN VOICE AI TODAY
It is not accuracy on clean English audio. Most platforms have that covered. The gap is in low-resource languages, where training data is scarce, dialect variation is high, and users cannot simply be asked to speak differently. That is the problem Shunyalabs was built to solve.
Why Research-Led Is an Architecture Choice, Not a Tagline
There is a meaningful difference between companies that build foundational speech models and companies that package other people’s models. The distinction matters enormously in production.
At Shunyalabs, every model we ship, whether for speech recognition, speech synthesis, or anything in between, is built and trained by our own research team. We collect data, design architectures, run experiments, and publish findings. That is what research-led means in practice.
Why does this matter for an enterprise client? A few concrete reasons.
When a model underperforms on a specific dialect or acoustic condition, the team that can fix it is the same team that built it. There is no waiting for a vendor upstream to push a patch. When you have a domain-specific vocabulary, say, medical terminology in Bengali or financial product names in Telugu, we can fine-tune for it directly. And when our models are tested against real-world noise, the findings feed back into training rather than being filed away as known limitations.
You can tell a research-led platform from a product wrapper the moment something breaks in production. One has answers. The other has a support ticket.
This approach also shapes how we think about languages. Building good speech AI for a low-resource language is a genuine research challenge. It requires collecting and cleaning training data where little exists, designing model architectures that handle high morphological complexity, and evaluating accuracy in conditions that reflect how people actually speak. We have done that work across 200 languages, including 55 Indic languages.
200 Languages Including 55 Indic: What This Actually Represents
Supporting a language and supporting it well are two different things. Plenty of platforms will list a language as “available” while quietly delivering word error rates that would be unacceptable in any real deployment. At Shunyalabs, our 200-language coverage is the result of deliberate, years-long research investment.
The 55 Indic languages we support include all the major languages in India. And beyond that, our language coverage spans Southeast Asia, the Middle East, Sub-Saharan Africa, and Latin America. These are among the fastest-growing internet markets in the world, and voice interfaces are particularly important in regions where literacy rates or typing habits make text-based interaction a barrier rather than a bridge.
For any enterprise deploying products across multiple geographies, this breadth means one platform instead of a patchwork of regional vendors. One integration, one contract, one team to work with.
Speech Recognition and Speech Synthesis, Both Done Right
Enterprise voice AI is not just about transcribing what people say. It is equally about how your product speaks back. The quality of a synthesised voice shapes how users perceive your brand, how much they trust the interaction, and whether they keep using the product at all.
At Shunyalabs, we have applied the same research rigour to speech synthesis that we have to recognition. Our text-to-speech models are built in-house, trained on high-quality data across multiple languages, and designed to produce natural, expressive output rather than the flat, mechanical voices.
This matters most in languages outside English, where the gap between good and mediocre synthesis is largest. A voice bot that understands Hindi perfectly but responds in an unnatural voice loses the trust it just built. Both sides of the conversation need to work.
The result is a full speech AI platform covering the complete voice interaction loop. You can explore our models at shunyalabs.ai.
Built for Enterprise Deployments From the Ground Up
Enterprise is not a pricing tier at Shunyalabs. It is the product philosophy. The requirements of large-scale deployments have shaped every architectural decision we have made.
DATA PRIVACY AND SOVEREIGNTY
Private cloud and on-premise deployment options. Your audio data never leaves your environment unless you want it to.
REAL-TIME PERFORMANCE AT SCALE
Streaming ASR and TTS built to handle thousands of concurrent sessions without latency creep or accuracy degradation.
DOMAIN ADAPTATION
Customise models on your vocabulary. Medical, legal, financial, or any other domain where off-the-shelf accuracy is not enough.
CLEAN API INTEGRATION
Well-documented APIs with SDKs that are easy to integrate.
OBSERVABILITY BUILT IN
Usage analytics, and performance dashboards so your team can monitor what matters.
ACCESS TO THE RESEARCH TEAM
When something needs solving, you talk to the people who built the model. Not a first-line support agent working from a script.
The on-premise preference is especially important to flag. Across the voice AI market, more than 62% of enterprise deployments favour on-premise setups, driven by data residency requirements and compliance in sectors like banking, healthcare, and government (Market.us).
Where Shunyalabs Makes the Biggest Difference
Contact centres and customer support automation. Multilingual voice bots handling inbound queries across Hindi, Tamil, Telugu, and Bengali are not a proof-of-concept for us. They are reference deployments. Real-time transcription, intent detection, and agent-assist functionality across 55 Indic languages, in production.
Banking and financial services. Tier 2 and Tier 3 markets in India represent hundreds of millions of customers who have historically been underserved by digital banking because the interface was built for English speakers. Voice AI in local languages changes that. Precise transcription of account numbers, transaction details, and product names in regional languages is something our models are specifically trained for.
Healthcare and public services. Patients describing symptoms in Kannada or Odia over a phone line need more than a best-effort transcript. These conversations have real consequences. Our models handle dialectal variation, low-bandwidth audio, and domain-specific medical vocabulary in a way that generic models simply do not.
EdTech and learning platforms. A child learning to read in Nagaland needs a speech-enabled tool that recognises their pronunciation, not a model calibrated for a studio-recorded American English dataset. We build for the actual learner, not the ideal one.
Media, content, and localisation. With our models covering 200 languages, enterprises building multilingual content pipelines can produce natural-sounding audio at scale without the cost and logistics of recording studios and voice actors for every language variant.
The Question That Separates Good Platforms From Great Ones
Before committing to any speech AI platform, ask the team one question: can you show me the model performing on real audio in the specific language and domain I care about?
Not a spec sheet. Not a word error rate on a benchmark dataset. Real audio, your language, your use case. A demo that holds up under those conditions tells you more than any marketing page.
At Shunyalabs, we welcome that question. Our models have been tested on real audio, regional dialects, low-literacy speakers, and every condition that shows up in real enterprise deployments. We are confident in what they can do because we built them to do it.
A Final Thought
The voice AI market is growing fast and getting more crowded by the month. Most of the new entrants are moving quickly, and some are doing interesting work. But there is a difference between moving quickly and building something that lasts.
Shunyalabs was built on research. That means our foundations are solid in a way that product wrappers are not. It means our language coverage is real. It means when the hard problems come, as they always do in production deployments, we have the tools and the people to solve them.
If you are evaluating speech AI platforms for an enterprise deployment, especially one that needs to perform across India or any high-language-diversity market, we would like to show you what we have built. Visit shunyalabs.ai/contact to start a conversation.
References
- bhavanishiva91@gmail.com (2025). Regional Language Content is the Next Big Thing for Indian. [online] atomcomm.in. Available at: https://atomcomm.in/regional-language-content-indian-digital-campaigns/.
- Iamai.in. (2025). Internet in India 2024 : Kantar_IAMAI Report | IAMAI. [online] Available at: https://www.iamai.in/research/internet-india-2024-kantariamai-report.
- Market.us. (2025). Voice AI Infrastructure Market. [online] Available at: https://market.us/report/voice-ai-infrastructure-market/.
- MarketsandMarkets. (2024). AI Voice Generator Market Size, Share and Global Forecast to 2030 | MarketsandMarkets. [online] Available at: https://www.marketsandmarkets.com/Market-Reports/ai-voice-generator-market-144271159.html.
- Private, I. (2026). Voice Recognition Market Growing at 22.38% CAGR to 2031 Driven by AI and Conversational Technologies says a 2026 Mordor Intelligence Report. [online] GlobeNewswire News Room. Available at: https://www.globenewswire.com/news-release/2026/01/26/3225814/0/en/Voice-Recognition-Market-Growing-at-22-38-CAGR-to-2031-Driven-by-AI-and-Conversational-Technologies-says-a-2026-Mordor-Intelligence-Report.html [Accessed 19 Mar. 2026].