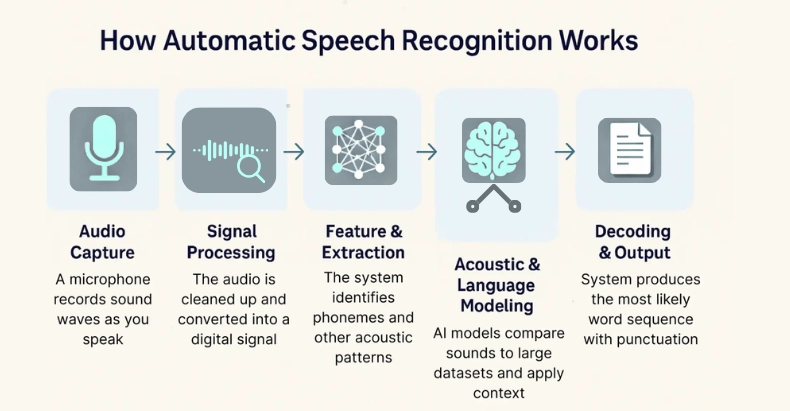
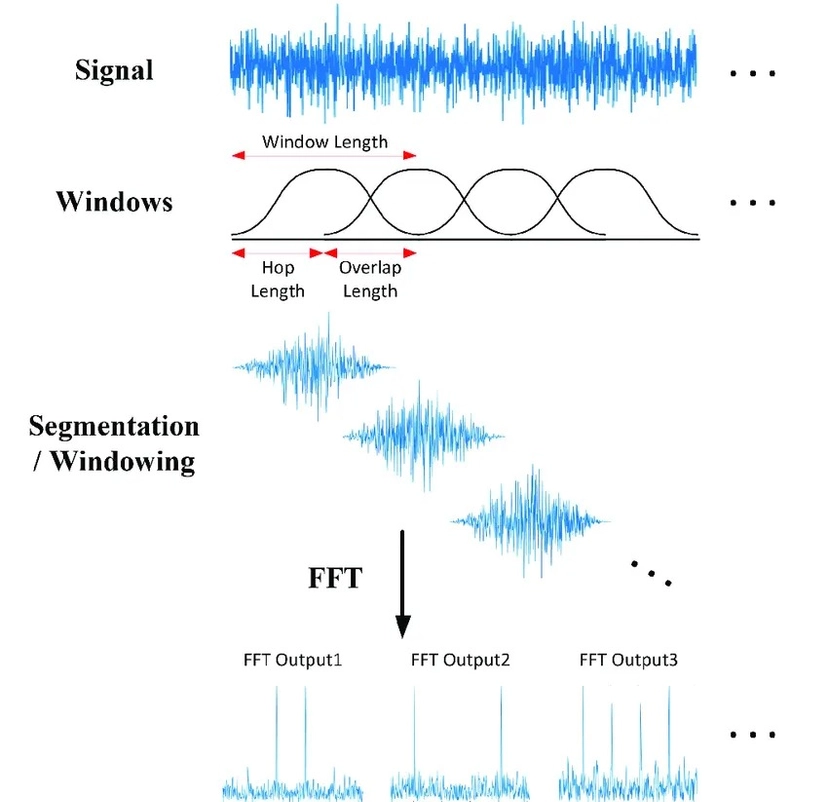
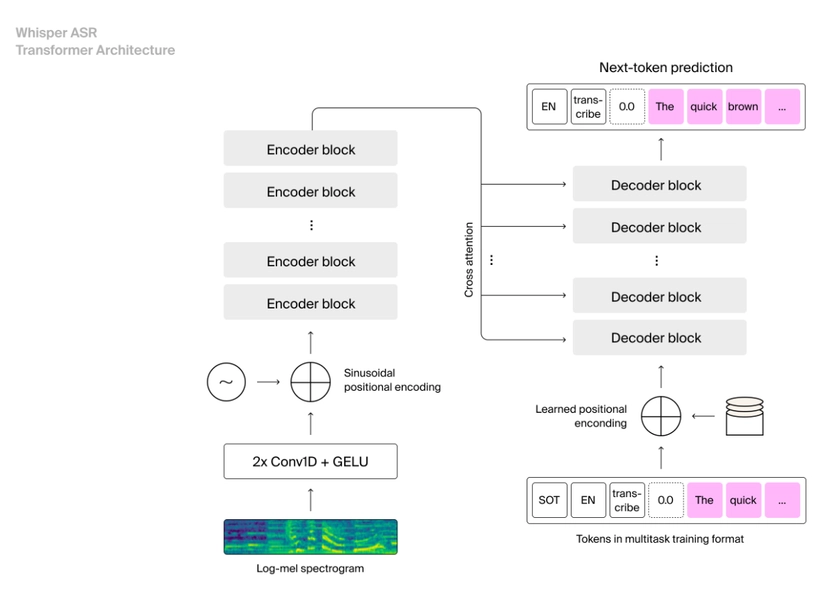
Ever wonder how your phone transcribes your voice messages or how virtual assistants understand your commands? The magic behind it is Automatic Speech Recognition (ASR). ASR APIs allow developers to integrate this powerful technology into their own applications.
What is an ASR API?
An ASR API is a service that converts spoken language (audio) into written text. You send an audio file to the API, and it returns a transcription. This is incredibly useful for a wide range of applications, from creating subtitles for videos to enabling voice-controlled interfaces and analyzing customer service calls.
This simple process enables complex features like:
- 🎬 Auto-generated subtitles
- 🗣️ Voice-controlled applications
- 📞 Speech analytics for customer calls
Before we dive into the code, you’ll need two things for most ASR providers:
- An API Key: Sign up with an ASR provider (like Google Cloud Speech-to-Text, AssemblyAI, Deepgram, or AWS Transcribe) to get your unique API key. This key authenticates your requests.
- An Audio File: Have a sample audio file (e.g., in .wav, .mp3, or .m4a format) ready to test. For this guide, we’ll assume you have a file named
my-audio.wav. - API Endpoint: The URL for the service, which we’ll assume is
https://api.shunya.org/v1/transcribe.
Integrating ASR APIs with Python
Automatic Speech Recognition (ASR) APIs allow your applications to convert spoken language into text, unlocking powerful new user experiences. Let’s go step by step so you can confidently integrate ASR APIs—using Python.
We’ll use the requests library to handle all our communication with the API.
Step 1: Set Up Your Environment
First, create a virtual environment and install requests.
# Create and activate a virtual environment
python -m venv venv
source venv/bin/activate # On Windows, use 'venv\Scripts\activate'
# Install the necessary library
pip install requestsStep 2: Building the Python Script
Create a file named transcribe_shunya.py and let’s build it section by section.
Part A: Configuration
First, we’ll import the necessary libraries and set up our configuration variables at the top of the file. This makes them easy to change later.
# transcribe_shunya.py
import requests
import time
import sys
# --- Configuration ---
API_KEY = "YOUR_SHUNYA_LABS_API_KEY"
API_URL = "https://api.shunya.org/v1/transcribe"
AUDIO_FILE_PATH = "my_punjabi_audio.wav"
# --------------------Here’s what each variable does:
- API_KEY: Your personal authentication token.
- API_URL: The endpoint where transcription jobs are submitted.
- AUDIO_FILE_PATH: Path to your local audio file.
Part B: Submitting the Transcription Job
This function handles the initial POST request. It opens your audio file, specifies the language model (pingalla), and sends it all to the API to start the process.
def submit_transcription_job(api_url, api_key, file_path):
"""Submits the audio file to the ASR API and returns the job ID."""
print("1. Submitting transcription job...")
headers = {"Authorization": f"Token {api_key}"}
# Specify language and model; adjust based on API docs
payload = {
"language": "pn",
"model": "pingala-v1"
}
try:
# We open the file in binary read mode ('rb')
with open(file_path, 'rb') as audio_file:
# The 'files' dictionary is how 'requests' handles multipart/form-data
files = {'audio_file': (file_path, audio_file, 'audio/wav')}
response = requests.post(api_url, headers=headers, data=payload, files=files)
response.raise_for_status() # This will raise an error for bad responses (4xx or 5xx)
job_id = response.json().get("job_id")
print(f" -> Job submitted successfully with ID: {job_id}")
return job_id
except requests.exceptions.RequestException as e:
print(f" -> Error submitting job: {e}")
return NonePart C: Displaying the Transcription Result
Once the API finishes processing, it returns a JSON response containing your transcription and metadata.
def print_transcription_result(result):
"""Display transcription text and segments."""
if not result or not result.get("success"):
print("❌ Transcription failed.")
return
print("\n✅ Transcription Complete!")
print("=" * 50)
print("Final Transcript:\n")
print(result.get("text", "No transcript found"))
print("=" * 50)
# Optional: print speaker segments
if result.get("segments"):
print("\nSpeaker Segments:")
for seg in result["segments"]:
print(f"[{seg['start']}s → {seg['end']}s] {seg['speaker']}: {seg['text']}")Part D: Putting It All Together
Finally, the main function orchestrates the entire process by calling our functions in the correct order. The if __name__ == "__main__": block ensures this code only runs when the script is executed directly.
def main():
"""Main function to run the transcription process."""
result = submit_transcription_job(API_URL, API_KEY, AUDIO_FILE_PATH)
if result:
print_transcription_result(result)
if __name__ == "__main__":
main()Step 3: Run the Python Script
With your audio file in the same folder, run:
python transcribe_shunya.pyIf everything’s set up correctly, you’ll see:
1. Submitting transcription job…
-> Job submitted successfully with ID: abc123
✅ Transcription Complete!
==================================================
Final Transcript:
ਸਤ ਸ੍ਰੀ ਅਕਾਲ! ਤੁਸੀਂ ਕਿਵੇਂ ਹੋ?
==================================================How It Works Behind the Scenes
Here’s what your script actually does step by step:
- Upload: The script sends your audio and metadata to ShunyaLabs’ ASR REST API.
- Processing: The backend model (Pingala V1) performs multilingual ASR, handling Indian languages, accents, and speech clarity.
- Response: The API returns a JSON response with:
- Full text transcript
- Timestamps for each segment
- Speaker diarization info (if enabled)
This same pattern — submit → poll → retrieve — is used by nearly every ASR provider, from Google Cloud to AssemblyAI to Pingala.
You can also use WebSocket streaming for near real-time transcription at:
wss://tb.shunyalabs.ai/ws
Best Practices
- Keep files under 10 MB for WebSocket requests (REST supports larger).
- Store API keys securely:
export SHUNYA_API_KEY="your_key_here" - Use clean mono audio (16kHz) for best accuracy.
- Experiment with parameters like:
--language-code hifor Hindi--output-script Devanagarifor Hindi text output
- Enable diarization to detect who’s speaking in multi-speaker audio.
Using the REST API Directly (Optional)
If you prefer using curl, try this:
curl -X POST "https://tb.shunyalabs.ai/transcribe" \
-H "X-API-Key: YOUR_SHUNYALABS_API_KEY" \
-F "file=@sample.wav" \
-F "language_code=auto" \
-F "output_script=auto"The API responds with JSON:
{
"success": true,
"text": "Good morning everyone, this is a sample transcription using ShunyaLabs ASR.",
"detected_language": "English",
"segments": [
{
"start": 0.0,
"end": 3.5,
"speaker": "SPEAKER_00",
"text": "Good morning everyone"
}
]
}Final Thoughts
You’ve just built a working speech-to-text integration using Python and the ShunyaLabs Pingala ASR API – the same foundation that powers real-time captioning, transcription tools, and voice analytics platforms.
With its multilingual support, low-latency WebSocket streaming, and simple REST API, Pingala makes it easy for developers to integrate accurate ASR into any workflow – whether you’re building for India or the world.
Automatic Speech Recognition bridges the gap between humans and machines, making technology more natural and inclusive.
As models like Pingala V1 continue advancing in language accuracy and CPU efficiency, ASR is becoming not just smarter, but also more accessible — ready to transform every app that can listen.